

Headless browser automation is an essential component for web scraping, allowing for various actions, such as scrolling, clicking buttons, and submitting forms. But about extending the headless browser's capabilities with Chrome extensions!
In this article, we'll explain how to install Chrome extensions with various headless browser libraries, such as Selenium, Playwright and Puppeteer. We'll also explore different useful Chrome extensions for web scraping. Let's dive in!
Key Takeaways
Master browser extensions for web scraping with advanced automation tools, Chrome extension integration, and anti-detection techniques for comprehensive scraping workflows.
- Configure Chrome extensions with Selenium, Playwright, and Puppeteer for enhanced web scraping capabilities
- Implement playwright chrome extension integration for advanced automation and anti-detection capabilities
- Use specialized extensions for network monitoring, request interception, and data extraction
- Configure browser automation with extension support for advanced scraping scenarios
- Use specialized tools like ScrapFly for automated extension management with anti-blocking features
- Implement proper extension configuration and error handling for reliable scraping workflows
Do Headless Browsers Support Chrome Extensions?
Google Chrome extensions are built on top of the Chromium engine, which is also used by other popular web browsers such as Microsoft Edge. Most headless browser automation libraries, such as Selenium, support the Google Chrome WebDriver. Therefore, it's possible to use Chrome extensions with headless browser libraries.
By default Chrome extensions can't run in the headless mode, as it requires a few layers found on the actual browser GUI. However, using the experimental option --headless new or --headless chrome can enable extension use in the headless mode. This option is still new and can be unstable.
Why Use Browser Extensions While Web Scraping?
There are numerous extensions available for Google Chrome that provide additional features and functionalities to the web browser. These extensions can be utilized with different stages of the web scraping process, from establishing the HTTP connection to the HTML parsing. To solidify this concept, let's have a look at a few useful Chrome extensions for Web Scraping.
Useful Chrome Extensions For Web Scraping
User-Agent Switcher
The User-Agent header is one of the most popular HTTP headers, which requires attention while web scraping. It includes different details about the request sender browser, such as the name, version and operating system. However, the User-Agent header used by headless browser libraries is common and many websites recognize it, leading to the request being identified and blocked. Therefore, the User-Agent switcher extension can be beneficial for avoiding web scraping blocking by rotating the User-Agent header.
Referer Control
The Referer header contains details of the previously visited domain URL, which is analyzed by antibots to determine if the request is automated. This header is automatically managed by the browser when navigating its web pages naturally. However, it can be neglected while web scraping specific pages and URLs. The Referer control extension can be used to define rules that automatically define this header on each website.
Canvas Fingerprint Defender
Websites can use the HTML Canvas to render images on the web page using the browser JavaScript. This image rendering can lead to creating a Canvas fingerprint, which includes various details about the operating system and browser. And since users browse the web through different operating systems and web browsers, this fingerprint is unique. However, the Canvas fingerprint of headless browsers is common, which allows websites to detect the usage of headless browsers. The Canvas fingerprint defender extension alters the browser details and feeds a fake fingerprint, preventing the headless browser from being detected.
We have only touched the surface of Chrome extensions for web scraping usage. Other useful extensions are:
-
WebRTC Control - Prevents the WebRTC leaks and hides the usage of How to Hide Your IP Address and The Complete Guide To Using Proxies For Web Scraping.
-
Postman Interceptor - Captures background XHR requests and syncs their configurations, including headers and cookies, to the Postman HTTP client. This extension comes in handy when using hidden APIs for web scraping.
-
SelectorsHub - Automatically writes and verifies Parsing HTML with Xpath and Parsing HTML with CSS Selectors selectors for elements on the HTML.
Setup
In this article, we'll explain how to install Chrome extensions with Selenium, Playwright and Puppeteer. Selenium and Playwright can be installed in Python using the following pip command:
pip install selenium webdriver-manager playwrightThe above command will install Selenium and the webdriver-manager, which we'll use later to install the ChromeDriver required by Selenium. As for Playwright's web drivers, they can be installed using the following command:
playwright installFor puppeteer, it can be installed in Node.js using npm or yarn:
npm install puppeteer
# or
yarn add puppeteerFor this article, we'll be using the famous Ad Blocker extension with each headless browser library. To start, we need to get the actual extension binaries in the crx format. We can download the extension binaries in different ways, such as the crxextractor tool or the Get CRX Chrome extension. After downloading the crx file, move it to the directory where the code will be executed.
The downloaded extension file will only work in Selenium. However, for Playwright and Puppeteer, we need to extract the file to get its source code. To do that, simply rename the file to change its format to .zip and then extract the zip file content.
Now that we have the extension in both formats, crx and extracted folder. Let's install it with the headless browser libraries!
Chrome Extensions in Selenium
To load Chrome extensions in Selenium, we can use either the unpacked extension folder or the packed crx file:
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# get the absoulte path of te extension folder
path_to_extension = os.path.abspath("./AdBlock")
options = webdriver.ChromeOptions()
options.add_extension("./AdBlock.crx") # load the extension using the crx file
options.add_argument(f"load-extension={path_to_extension}") # load the extension using the unpacked folder
# automatically install the ChromeDriver binaries and the configured options
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
# go the Chrome extensions page
driver.get("chrome://extensions/")
# take a screenshot
driver.save_screenshot('selenium_chrome_extensions.png')
# close the browser
driver.quit()Here, we load the Chrome extension to Selenium WebDrvier twice in two different ways. The first one is using the packed extension through the add_extension method. The other one is using the extracted extention through the add_argument method. Next, we use webdriver_manager to install the Chrome web driver and load the previously created options. Finally, we head over to the Chrome extensions page and take a screenshot. Here is the screenshot we got:
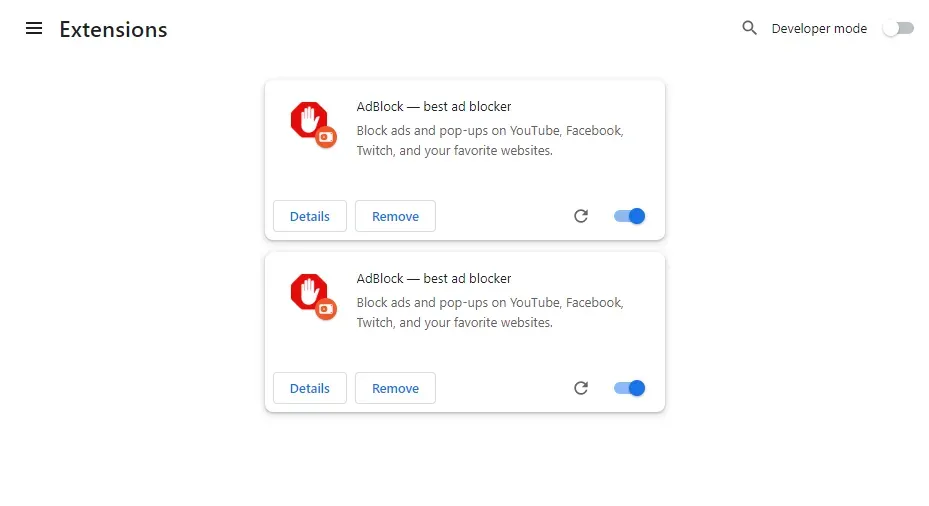
Our Selenium Chrome extensions installation is a success. However, the extensions can require additional configurations for optimal usage, especially when web scraping. Let's automate the extension configurations from our code:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
def update_extension_options():
"""click option buttons"""
# CSS selectors of the option checkboxex
elements = ["#acceptable_ads_privacy", "#enable_twitch_channel_allowlist",
"#enable_data_collection_v2"]
for element in elements:
driver.find_element(By.CSS_SELECTOR, f"{element}").click()
options = webdriver.ChromeOptions()
options.add_extension("./AdBlock.crx") # load the extension using the crx file
# automatically install the ChromeDriver binaries and the configured options
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
# wait the extension to finish installation
time.sleep(10)
# go to the extension options
driver.get("chrome-extension://gighmmpiobklfepjocnamgkkbiglidom/options.html#general")
# update the extension options
update_extension_options()
# take a screenshot
driver.save_screenshot('selenium_chrome_extensions.png')
# close the browser
driver.quit()The above code is almost the same as the previous snippet except for a few changes. We defined an update_extension_options function, which iterates over a few option buttons and clicks each button using CSS selectors. Then, we head over the extension options page and call the function we defined to update it. Here are the updated options:
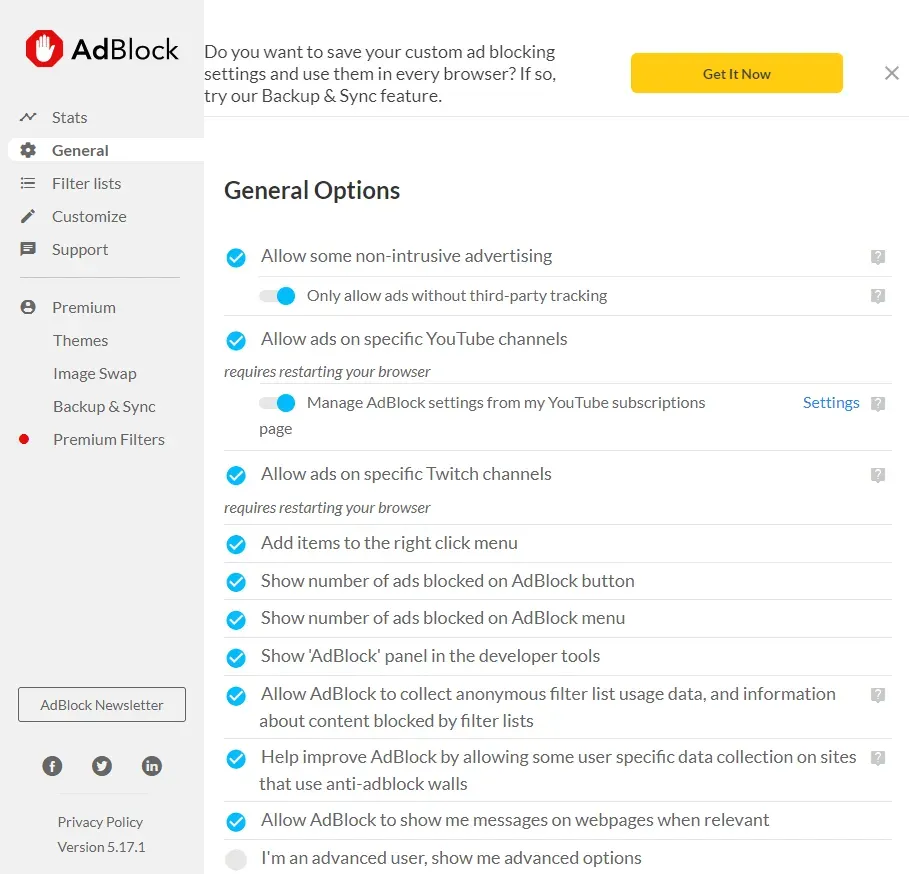
We have successfully installed a Chrome extension with Selenium and updated its options. Although we have covered a simple extension, this process can be applied to other extensions.
For more details on Selenium, refer to our previous article.

Chrome Extensions in Playwright
Playwright Chrome extensions can only be added using the unpacked extension folder:
import os
from playwright.sync_api import sync_playwright
path_to_extension = os.path.abspath("./AdBlock")
user_data_dir = "./"
with sync_playwright() as playwright:
# intialize a persistent Chrome instance
context = playwright.chromium.launch_persistent_context(
# user data directory argument is required
user_data_dir,
# run the browser headful mode
headless=False,
# add the Chrome extension
args=[
f"--disable-extensions-except={path_to_extension}",
f"--load-extension={path_to_extension}",
],
)
# intitialize a new browser page
page = context.new_page()
# go the Chrome extensions page
page.goto("chrome://extensions/")
# take a screenshot
page.screenshot(path="playrwight_chrome_extensions.png")Here, we initialize a sync Playwright instance in the headful mode. Next, we add the Chrome extention to the browser using the load-extension argument. Finally, we request the Chrome extension page and take a screenshot.
The next step is to update the extension options like we did before:
import os
import time
from playwright.sync_api import sync_playwright
path_to_extension = os.path.abspath("./AdBlock")
user_data_dir = "./"
def update_extension_options():
"""click option buttons"""
# CSS selectors of the option checkboxex
elements = ["#acceptable_ads_privacy", "#enable_twitch_channel_allowlist",
"#enable_data_collection_v2"]
for element in elements:
page.click(element)
with sync_playwright() as playwright:
# intialize a persistent Chrome instance
context = playwright.chromium.launch_persistent_context(
# user data directory argument is required
user_data_dir,
# run the browser headful mode
headless=False,
# add the Chrome extension
args=[
f"--disable-extensions-except={path_to_extension}",
f"--load-extension={path_to_extension}",
],
)
# intitialize a new browser page
page = context.new_page()
# wait the extension to finish installation
time.sleep(10)
# go to the extension options
page.goto("chrome-extension://agmafgjokfhoibnnnppdbpkddlibhmme/options.html#general")
# update the extension options
update_extension_options()
# take a screenshot
page.screenshot(path="playrwight_chrome_extensions.png")Here, we add additional functionality to our code. We wait for 10 seconds for the extension to finish the installation and then head over to the extension options page. Finally, we update the extension options using selectors and take a screenshot.
The above script is implemented for the Python version of Playwright. However, you can apply it for different Playwright clients in other languages, as the underlying API is the same.
For more details about Playwright, refer to our previous article.

Chrome Extensions in Puppeteer
Similar to Playwright, Puppeteer Chrome extensions can be added using the unpacked extension folder:
const puppeteer = require('puppeteer');
const path = require('path');
// get the absolute extension path
const pathToExtension = path.join(process.cwd(), 'AdBlock');
async function run(){
// launch a browser instance
const browser = await puppeteer.launch({
// launch the browser in the headful mode
headless: false,
// add the extension to the browser
args: [
`--disable-extensions-except=${pathToExtension}`,
`--load-extension=${pathToExtension}`,
],
});
// open a new browser tab
let page = await browser.newPage();
// go the Chrome extensions page
await page.goto('chrome://extensions/');
// take a screenshot
await page.screenshot({ path: `./puppeteer_chrome_extensions.png` });
// close the tab and browser
await page.close();
await browser.close();
};
run();In the above code, we launch a browser and add the extension using the load-extension argument. Then, we go to the Chrome extensions page and take a screenshot.
The next step is to modify the extension options as we did before:
const puppeteer = require('puppeteer');
const path = require('path');
const { setTimeout } = require('timers/promises');
// get the absolute extension path
const pathToExtension = path.join(process.cwd(), 'AdBlock');
async function updateExtensionOptions(page){
// CSS selectors of the option checkboxex
elements = ["#acceptable_ads_privacy", "#enable_twitch_channel_allowlist",
"#enable_data_collection_v2"]
for (const element of elements) {
await page.click(element);
};
};
async function run(){
// launch a browser instance
const browser = await puppeteer.launch({
// launch the browser in the headful mode
headless: false,
// add the extension to the browser
args: [
`--disable-extensions-except=${pathToExtension}`,
`--load-extension=${pathToExtension}`,
],
});
// wait the extension to finish installation
await setTimeout(10000);
// open a new browser tab
let page = await browser.newPage();
// go to the extension options
await page.goto("chrome-extension://agmafgjokfhoibnnnppdbpkddlibhmme/options.html#general")
// update the extension options
await updateExtensionOptions(page)
// take a screenshot
await page.screenshot({ path: `./puppeteer_chrome_extensions.png` });
// close the tab and browser
await page.close();
await browser.close();
};
run();Here, we define an updateExtensionOptions function, which iterates over option elements to update them. Next, we call this function after requesting the extension options page, take a screenshot and close the browser.
For more details about Puppeteer, refer to our previous article.

FAQ
How to install Chrome extensions in Selenium Python?
To install Chrome extensions with Selenium, you can either use the packed extension file in crx or the extracted extension folder. Next, you can load the extension into the browser using the add_extension method when using the packed file or using the load-extension argument when using the extracted extension folder.
Can I run browser extensions in the headless mode?
At the time of writing, Chromium browsers don't support extensions in the headless mode by default but the experimental option --headless new or --headless chrome can enable extension use in the headless mode.
How to get Chrome extension files for headless browsers?
To get the Chrome extension source, you can either use 3rd party tools, such as the crxextractor and Get CRX extension, or you can copy them manually from your operating system files.
Headless Browser Extensions Summary
Browser extensions are add-on tools that add more capabilities to the web browser. We have seen that using Chrome extensions for web scraping can add additional features, such as avoiding blocking and assisting in HTML parsing.
We have also gone through a step-by-step guide on installing Chrome extensions with different headless browser libraries, such as Selenium, Playwright and Puppeteer.


