

Walmart.com is a major global retailer with a significant presence in the United States. Due to its extensive reach, Walmart's public product data is often in demand for competitive intelligence analytics. In 2026, Walmart uses Next.js with structured JSON in __NEXT_DATA__ script tags, making hidden data extraction more reliable than traditional CSS selector parsing. So, how can we effectively extract this valuable product data through web scraping?
In this article, we'll explain how to scrape Walmart product data with Python. We'll start by reverse engineering the website to find products using sitemaps, category links and the search API. Then, we'll use hidden data parsing techniques to scrape a vast amount of product data using minimum lines of code. Let's get started!
Key Takeaways
Build a Walmart scraper using Python to extract product data and reviews from hidden API endpoints, handling dynamic content and anti-bot measures for e-commerce analysis.
- Reverse engineer Walmart's search API endpoints by intercepting browser network requests
- Parse dynamic JSON data embedded in HTML using XPath selectors for product details and variants
- Bypass Walmart's anti-scraping measures with realistic headers, user agents, and request spacing
- Extract structured product data including titles, prices, descriptions, and review information
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use specialized tools like ScrapFly for automated Walmart scraping with anti-blocking features
Why Scrape Walmart?
Walmart is one of the largest e-commerce platforms in the US, containing thousands of products in various categories. Businesses can scrape Walmart's data to understand the market trends and track price changes.
Walmart also features user ratings and detailed reviews on each product, which can be challenging to read and analyze manually. By scraping Walmart reviews, we can use machine learning, such as sentiment analysis, to study the users' opinions and experiences with products and sellers.
Moreover, manually navigating a comprehensive set of products on Walmart.com can be time-consuming. Web scraping Walmart allows for retrieving thousands of listings quickly.
For further details, refer to our extensive article on web scraping e-commerce use cases.
Project Setup
To scrape Walmart, we'll use Python with a few community libraries:
- httpx - An HTTP client library we'll use to request Walmart pages.
- parsel - An HTML parsing library we'll use to parse the HTML using query languages, such as Parsing HTML with Xpath and Parsing HTML with CSS Selectors.
- loguru - A logging library we'll use to monitor our Walmart scraper.
- asyncio - A library we'll use to run our code asynchronously, increasing our web scraping speed.
Since asyncio comes pre-installed in Python, you will only have to install the other packages using the following pip command:
$ pip install httpx parsel loguruAlternatively, feel free to swap httpx out with any other HTTP client, such as requests. We'll only use basic HTTP functions found among different HTTP clients.
As for, parsel, another great alternative is beautifulsoup.
How to Find Walmart Products
Before we start scraping Walmart, we need to find and discover products on the website. We can approach this in two common ways.
The first approach is using Walmart's sitemaps. These sitemaps are found on Walmart's robots.txt instructions, which provide crawling rules for search engines to index its pages. We can make use of these sitemaps to navigate the website:
Sitemap: https://www.walmart.com/sitemap_category.xml
Sitemap: https://www.walmart.com/sitemap_store_main.xml
Sitemap: https://www.walmart.com/help/sitemap_gm.xml
Sitemap: https://www.walmart.com/sitemap_browse_fst.xml
Sitemap: https://www.walmart.com/sitemap_store_dept.xml
Sitemap: https://www.walmart.com/sitemap_tp_legacy.xml
Sitemap: https://www.walmart.com/sitemap_tp_at.xml
Sitemap: https://www.walmart.com/sitemap_tp_br.xml
Sitemap: https://www.walmart.com/sitemap_tp_kp.xml
...The above sitemap URLs don't provide enough room for use to filter results. However, we can use the category sitemap to filter results by category:
<url>
<loc>https://www.walmart.com/cp/the-pioneer-woman-patio-garden/6178203</loc>
<lastmod>2024-01-02</lastmod>
</url>
<url>
<loc>https://www.walmart.com/cp/the-ultimate-guide-to-curtain-rods/9857665</loc>
<lastmod>2024-01-02</lastmod>
</url>
<url>
<loc>https://www.walmart.com/cp/thor-party-supplies/7080475</loc>
<lastmod>2024-01-02</lastmod>
</url>
<url>
<loc>https://www.walmart.com/cp/trees/1388945</loc>
<lastmod>2024-01-02</lastmod>
</url>Each URL in the above sitemap will redirect us to the pagination page of a single category, which we can further customize with additional filters:
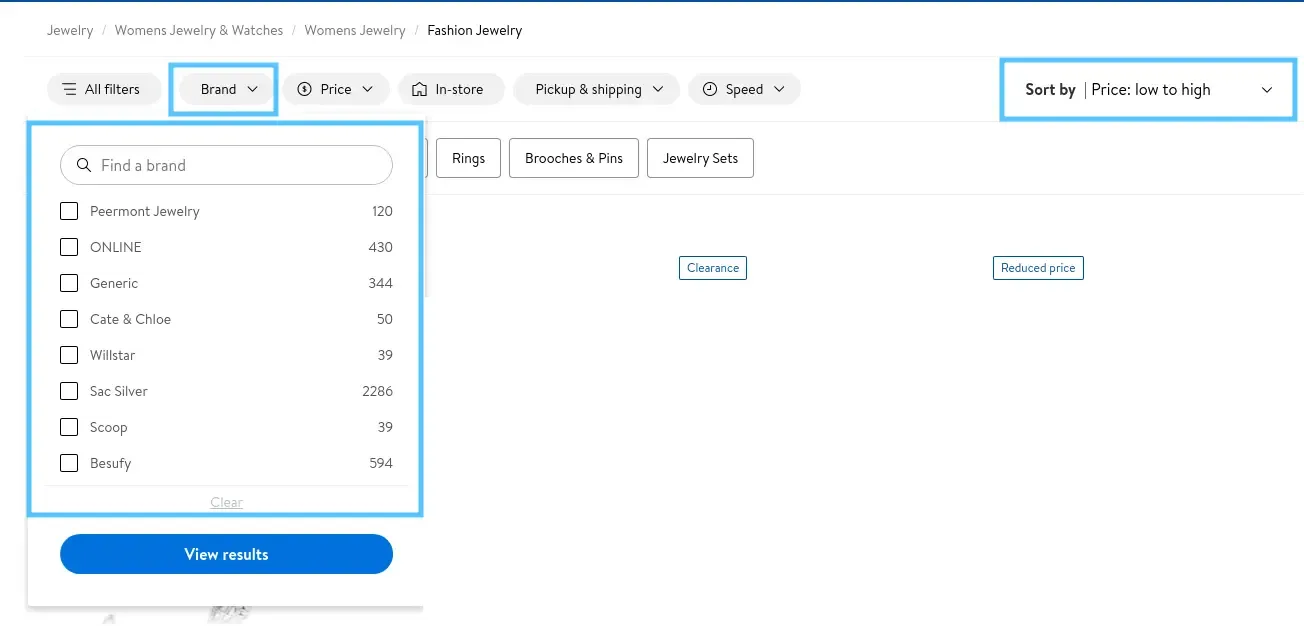
The second approach is using the search system, which allows for applying filters too. So, either way, we can use the same parsing logic as we are redirected to the same page. Now that we have an overview of how to find products on the website. Next, explore scraping Walmart's search for the actual product data.
How to Scrape Walmart Search
Before we start scraping search pages, let's have a look at what the search pages look like. Use any keyword to search for any product, such as "laptop", and you will get a page similar to this to the following:
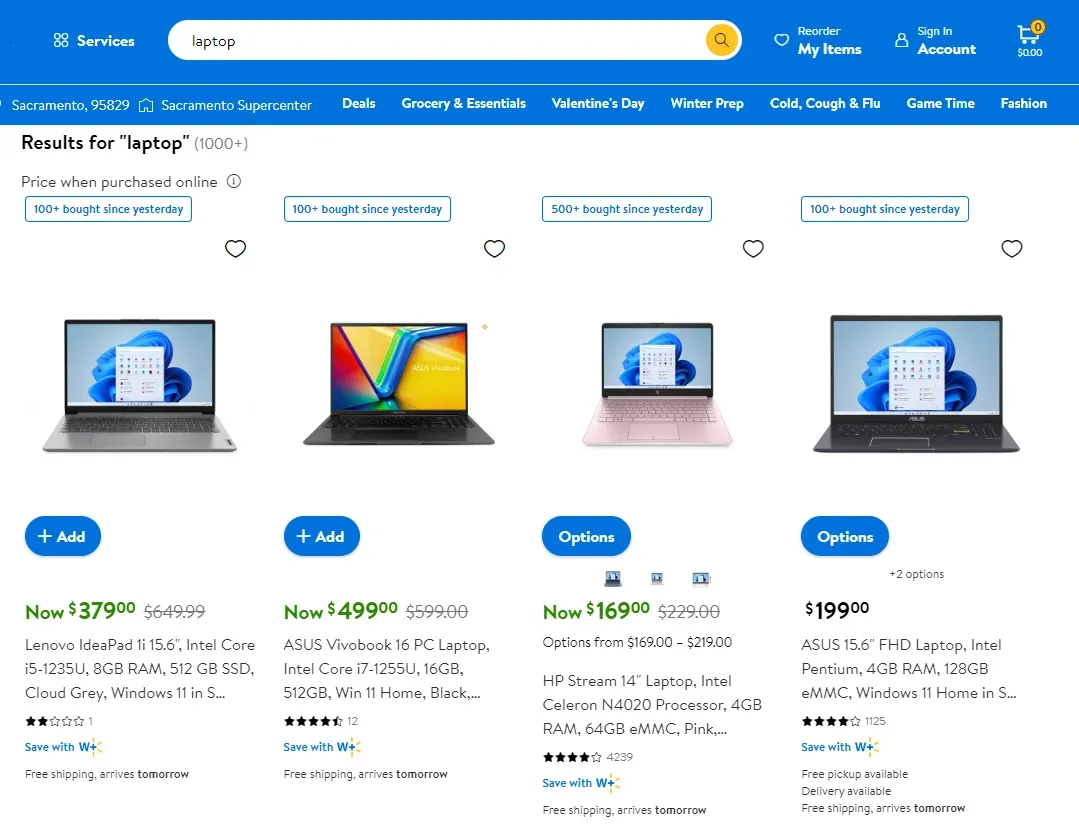
The search results can be customized using a few parameters with the URL:
https://www.walmart.com/search?q=laptop&sort=price_low&page=1&affinityOverride=defaultLet's break down the above URL parameters:
qstands for "search query" with the word "spider" as the value.pagestands for page number with the first result page as value.sortstands for sorting order with theprice_lowas value, sorted ascending by price.
Instead of parsing each product data from the HTML, we'll extract the data directly from the JavaScript in JSON format. To view this data, open the browser developer tools by pressing the F12 key and search for the script tag with the __NEXT_DATA__:
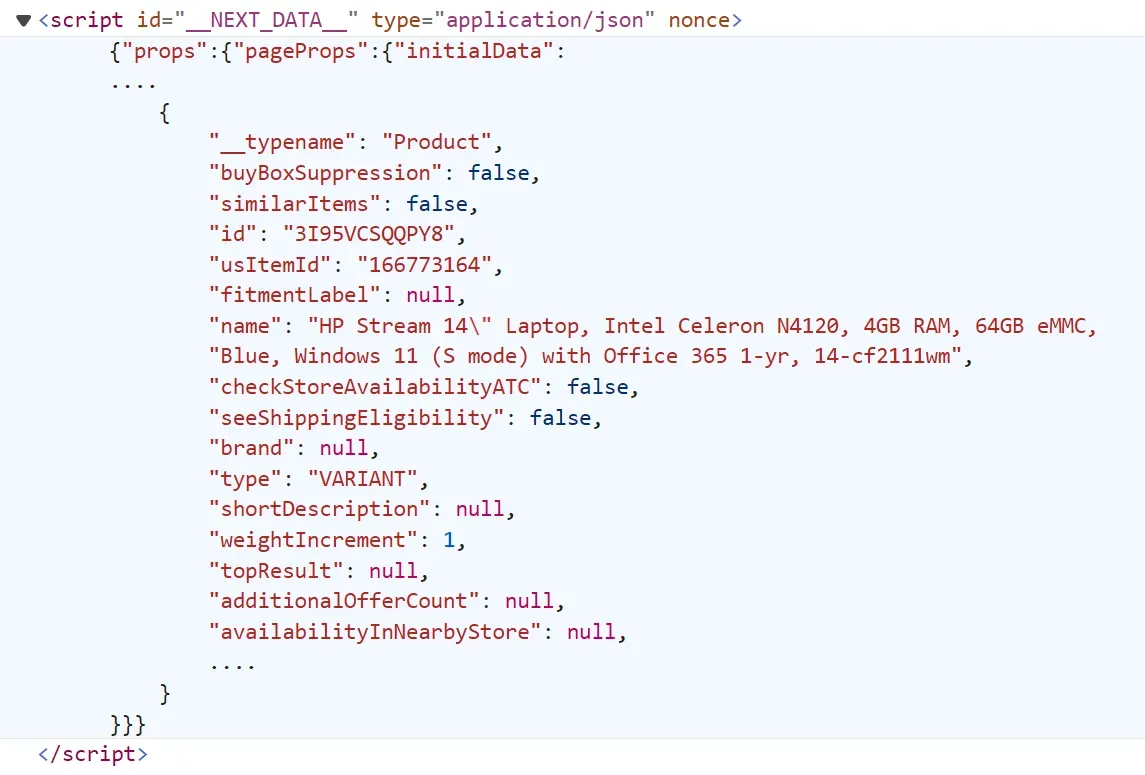
This data is the same on the page before it's rendered into the HTML, often known as hidden web data.
Let's start scraping Walmart search pages by defining our parsing log:
def parse_search(html_text:str) -> Dict:
"""extract search results from search HTML response"""
sel = Selector(text=html_text)
data = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
data = json.loads(data)
total_results = data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["count"]
results = data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
return results, total_resultsHere, we define a parse_search function. It locates the script tag with the data, extracts its data and loads it to a JSON object. It also extracts the total number of available pages, which we'll use later to crawl over search pages.
Next, we'll use this function while requesting Walmart pages to scrape its data:
import asyncio
import json
import math
import httpx
from urllib.parse import urlencode
from typing import List, Dict
from loguru import logger as log
from parsel import Selector
def parse_search(html_text:str) -> Dict:
"""extract search results from search HTML response"""
sel = Selector(text=html_text)
data = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
data = json.loads(data)
total_results = data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["count"]
results = data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
return results, total_results
async def scrape_walmart_page(session:httpx.AsyncClient, query:str="", page=1, sort="price_low"):
"""scrape a single walmart search page"""
url = "https://www.walmart.com/search?" + urlencode(
{
"q": query,
"sort": sort,
"page": page,
"affinityOverride": "default",
},
)
resp = await session.get(url)
assert resp.status_code == 200, "request is blocked"
return resp
async def scrape_search(search_query:str, session:httpx.AsyncClient, max_scrape_pages:int=None) -> List[Dict]:
"""scrape Walmart search pages"""
# scrape the first search page first
log.info(f"scraping Walmart search for the keyword {search_query}")
_resp_page1 = await scrape_walmart_page(query=search_query, session=session)
results, total_items = parse_search(_resp_page1.text)
# get the total number of pages available
max_page = math.ceil(total_items / 40)
if max_page > 25: # the max number of pages is 25
max_page = 25
# get the number of total pages to scrape
if max_scrape_pages and max_scrape_pages < max_page:
max_page = max_scrape_pages
# scrape the remaining search pages
log.info(f"scraped the first search, remaining ({max_page-1}) more pages")
for response in await asyncio.gather(
*[scrape_walmart_page(query=search_query, page=i, session=session) for i in range(2, max_page)]
):
results.extend(parse_search(response.text)[0])
log.success(f"scraped {len(results)} products from walmart search")
return resultsRun the code
BASE_HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate",
}
async def run():
# limit connection speed to prevent scraping too fast
limits = httpx.Limits(max_keepalive_connections=5, max_connections=5)
client_session = httpx.AsyncClient(headers=BASE_HEADERS, limits=limits)
# run the scrape_search function
data = await scrape_search(search_query="latpop", session=client_session, max_scrape_pages=3)
# save the results into a JSON file "walmart_search.json"
with open("walmart_search.json", "w", encoding="utf-8") as file:
json.dump(data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())In the above code, we define two additional functions, let's break them down:
scrape_walmart_page formats the search page URL using the search query alongside other filtering parameters and then requests the URL using httpx.
scrape_search: scrape the first search page to extract its data and the total number of pages available. Then, it adds the remaining search pages to a scraping list and scrapes them concurrently.
Finally, we run the code using asyncio, add normal browser headers to minimize the blocking chances and save the results to a JSON file. Here is a sample output of the results we got:
Sample output
[
{
"__typename": "Product",
"buyBoxSuppression": false,
"similarItems": false,
"id": "3ULHM02S22J4",
"usItemId": "791595618",
"fitmentLabel": null,
"name": "Restored Acer C720-2103 Celeron 2955U Dual-Core 1.4GHz 2GB 16GB SSD 11.6\" LED Chromebook Chrome OS w/Cam & BT (Refurbished)",
"checkStoreAvailabilityATC": false,
"seeShippingEligibility": false,
"brand": null,
"type": "REGULAR",
"shortDescription": "<li>Intel Celeron 2955U 1.4 GHz</li><li>2 GB DDR3L SDRAM</li><li>16 GB Solid-State Drive</li><li>11.6-Inch HD Screen, Intel HD Graphics</li><li>Google Chrome, Up to 8.5-hour battery life</li>",
"weightIncrement": 1,
"topResult": null,
"additionalOfferCount": 1,
"availabilityInNearbyStore": null,
"imageInfo": {
"id": "C4E513CC4FF043909A45FA427AD575B2",
"name": "4a315131-dad3-4390-8684-69588a98df7b.116044b89f26879827c88b62ebe1f34c.jpeg",
"thumbnailUrl": "https://i5.walmartimages.com/asr/4a315131-dad3-4390-8684-69588a98df7b.116044b89f26879827c88b62ebe1f34c.jpeg?odnHeight=180&odnWidth=180&odnBg=ffffff",
"size": "290-392"
},
"aspectInfo": {
"name": null,
"header": null,
"id": null,
"snippet": null
},
"canonicalUrl": "/ip/Restored-Acer-C720-2103-Celeron-2955U-Dual-Core-1-4GHz-2GB-16GB-SSD-11-6-LED-Chromebook-Chrome-OS-w-Cam-BT-Refurbished/791595618",
"externalInfo": null,
"itemType": null,
"category": {
"path": null
},
"badges": {
"flags": null,
"tags": [],
"groups": [
{
"__typename": "UnifiedBadgeGroup",
"name": "product_condition",
"members": [
{
"__typename": "BadgeGroupMember",
"id": "L1095",
"key": "PREOWNED",
"memberType": "badge",
"otherInfo": null,
"rank": 1,
"slaText": null,
"styleId": "REFURB_ICON_BLACK_TXT",
"text": "Restored",
"type": "ICON",
"templates": null,
"badgeContent": null
}
]
},
{
"__typename": "UnifiedBadgeGroup",
"name": "fulfillment",
"members": [
{
"__typename": "BadgeGroupMember",
"id": "L1053",
"key": "FF_SHIPPING",
"memberType": "badge",
"otherInfo": null,
"rank": 1,
"slaText": "in 3+ days",
"styleId": "FF_STYLE",
"text": "Free shipping, arrives ",
"type": "LABEL",
"templates": null,
"badgeContent": null
}
]
}
]
},
"classType": "REGULAR",
"averageRating": 3.5,
"numberOfReviews": 46,
"esrb": null,
"mediaRating": null,
"salesUnitType": "EACH",
"sellerId": "AB4FE66990144E52892BD488B4A01371",
"sellerName": "Ellison ProTech",
"hasSellerBadge": null,
"isEarlyAccessItem": false,
"earlyAccessEvent": false,
"annualEvent": false,
"annualEventV2": false,
"availabilityStatusV2": {
"display": "In stock",
"value": "IN_STOCK"
},
"groupMetaData": {
"groupType": null,
"groupSubType": null,
"numberOfComponents": 0,
"groupComponents": null
},
"productLocation": null,
"fulfillmentSpeed": null,
"offerId": "1A7423C9997D3653823BC92C7F49694B",
"preOrder": {
"isPreOrder": false,
"preOrderMessage": null,
"preOrderStreetDateMessage": null,
"streetDate": null,
"streetDateDisplayable": null,
"streetDateType": null
},
"pac": null,
"fulfillmentSummary": [
{
"storeId": "0",
"deliveryDate": null
}
],
"priceInfo": {
"itemPrice": "",
"linePrice": "$79.99",
"linePriceDisplay": "$79.99",
"savings": "",
"savingsAmt": 0,
"wasPrice": "",
"unitPrice": "",
"shipPrice": "",
"minPrice": 0,
"minPriceForVariant": "",
"priceRangeString": "",
"subscriptionPrice": "",
"subscriptionString": "",
"priceDisplayCondition": "",
"finalCostByWeight": false,
"submapType": "",
"eaPricingText": "",
"eaPricingPreText": "",
"memberPriceString": "",
"subscriptionDualPrice": null,
"subscriptionPercentage": null
},
....
"description": "<li>Intel Celeron 2955U 1.4 GHz</li><li>2 GB DDR3L SDRAM</li><li>16 GB Solid-State Drive</li><li>11.6-Inch HD Screen, Intel HD Graphics</li><li>Google Chrome, Up to 8.5-hour battery life</li>",
"flag": "",
"badge": {
"text": "",
"id": "",
"type": "",
"key": "",
"bundleId": ""
},
"fulfillmentBadges": [],
"fulfillmentBadgeGroups": [
{
"text": "Free shipping, arrives ",
"slaText": "in 3+ days",
"isSlaTextBold": true,
"templates": null,
"className": "dark-gray"
}
],
"specialBuy": false,
"priceFlip": false,
"image": "https://i5.walmartimages.com/asr/4a315131-dad3-4390-8684-69588a98df7b.116044b89f26879827c88b62ebe1f34c.jpeg?odnHeight=180&odnWidth=180&odnBg=ffffff",
"imageSize": "290-392",
"imageID": "C4E513CC4FF043909A45FA427AD575B2",
"imageName": "4a315131-dad3-4390-8684-69588a98df7b.116044b89f26879827c88b62ebe1f34c.jpeg",
"isOutOfStock": false,
"price": 79.99,
"rating": {
"averageRating": 3.5,
"numberOfReviews": 46
},
"salesUnit": "EACH",
"variantList": [],
"isVariantTypeSwatch": false,
"shouldLazyLoad": false,
"isSponsoredFlag": false,
"moqText": null
},
....
]Cool! With just a few lines of code, our Walmart scraper got detailed product data. It can also crawl over search pages and narrow down the search results.
How to Handle Walmart Pagination Limit
There is one minor downside with our previous Walmart scraping logic - the pagination limit. Walmart sets the maximum number of result pages that can be accessed to 25 regardless of the total number of pages available.
To get around this, we can split our scraping load into smaller batches, where each batch contains a shorter set of products:
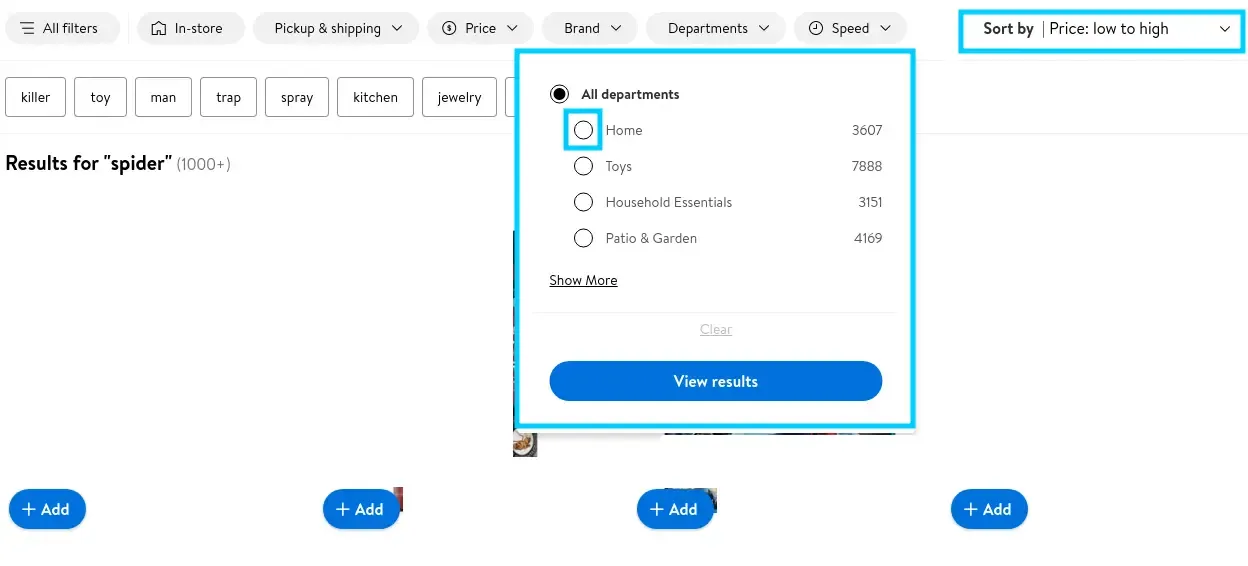
For example, we can reverse order the results. We can scrape lowest-to-highest ordered results and then reverse it - doubling our range to 50 pages or 2000 products!
Furthermore, we can split our query into smaller queries by using single-choice filters or go even further and use price ranges. So, with a bit of clever query splitting, this 2000 product limit doesn't look that intimidating!
How to Scrape Walmart Product Pages
In this section, we'll scrape Walmart product data from their pages. These pages contain various data points in different parts of the HTML, making it challenging to parse. Therefore, we'll extract the hidden data directly. Similar to search pages, product page data are found under JavaScript tags:
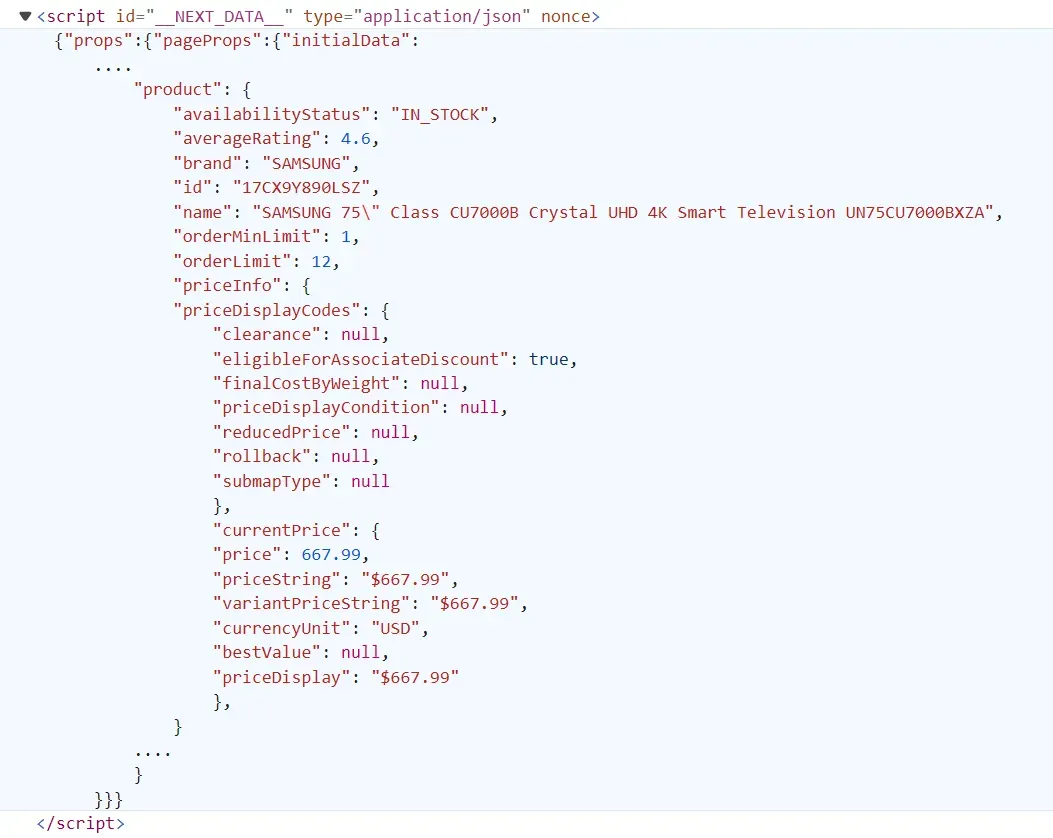
Now that we can locate the data, let's define our parsing logic:
def parse_product(html_text: str) -> Dict:
"""parse walmart product"""
sel = Selector(text=html_text)
data = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
data = json.loads(data)
_product_raw = data["props"]["pageProps"]["initialData"]["data"]["product"]
# There's a lot of product data, including private meta keywords, so we need to do some filtering:
wanted_product_keys = [
"availabilityStatus",
"averageRating",
"brand",
"id",
"imageInfo",
"manufacturerName",
"name",
"orderLimit",
"orderMinLimit",
"priceInfo",
"shortDescription",
"type",
]
product = {k: v for k, v in _product_raw.items() if k in wanted_product_keys}
reviews_raw = data["props"]["pageProps"]["initialData"]["data"]["reviews"]
return {"product": product, "reviews": reviews_raw}Here, we define a parse_product function. It selects the script tag with the data and loads it to a JSON object. Since the JSON dataset includes many unnecessary fields, we iterate over the data keys and select the actual product only.
Next, let's utilize the function we defined while sending to scrape product page data:
import asyncio
import json
import httpx
from typing import List, Dict
from loguru import logger as log
from parsel import Selector
def parse_product(html_text: str) -> Dict:
"""parse walmart product"""
sel = Selector(text=html_text)
data = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
data = json.loads(data)
_product_raw = data["props"]["pageProps"]["initialData"]["data"]["product"]
# There's a lot of product data, including private meta keywords, so we need to do some filtering:
wanted_product_keys = [
"availabilityStatus",
"averageRating",
"brand",
"id",
"imageInfo",
"manufacturerName",
"name",
"orderLimit",
"orderMinLimit",
"priceInfo",
"shortDescription",
"type",
]
product = {k: v for k, v in _product_raw.items() if k in wanted_product_keys}
reviews_raw = data["props"]["pageProps"]["initialData"]["data"]["reviews"]
return {"product": product, "reviews": reviews_raw}
async def scrape_products(urls: List[str], session:httpx.AsyncClient):
"""scrape Walmart product pages"""
log.info(f"scraping {len(urls)} products from Walmart")
responses = await asyncio.gather(*[session.get(url) for url in urls])
results = []
for resp in responses:
assert resp.status_code == 200, "request is blocked"
results.append(parse_product(resp.text))
log.success(f"scraped {len(results)} products data")
return resultsIn the above code, we define a scrape_products function. It iterates over the product URLs to request and parse each product page.
Run the code
async def run():
# limit connection speed to prevent scraping too fast
limits = httpx.Limits(max_keepalive_connections=5, max_connections=5)
client_session = httpx.AsyncClient(headers=BASE_HEADERS, limits=limits)
# run the scrape_products function
data = await scrape_products(
urls=[
"https://www.walmart.com/ip/1736740710",
"https://www.walmart.com/ip/715596133",
"https://www.walmart.com/ip/496918359",
],
session=client_session
)
# save the results into a JSON file "walmart_products.json"
with open("walmart_products.json", "w", encoding="utf-8") as file:
json.dump(data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())In the above code, we define a scrape_products function. It iterates over the product URLs to request and parse each product page. Finally, we execute the code using asyncio and save the results to a JSON file. Here is a sample output of the results we got:
Sample output
[
{
"product": {
"availabilityStatus": "IN_STOCK",
"averageRating": 4.8,
"brand": "PlayStation",
"shortDescription": "The PS5™ console unleashes new gaming possibilities that you never anticipated. Experience lightning fast loading with an ultra-high speed SSD, deeper immersion with support for haptic feedback, adaptive triggers, and 3D Audio*, and an all-new generation of incredible PlayStation® games.",
"id": "4S6KN6TWU0A0",
"imageInfo": {
"allImages": [
{
"id": "028D1C667CF9481482B7081F08C29D1C",
"url": "https://i5.walmartimages.com/seo/Sony-PlayStation-5-PS5-Video-Game-Console_9333b8cd-773e-49d4-8e85-51c4114fcd56.bbf5c4e4f3746ddc28ac982117cdbf9a.jpeg",
"zoomable": true
},
{
"id": "8B95F80972FA48FAA0413FA936155691",
"url": "https://i5.walmartimages.com/asr/985f6fea-1255-44f9-a4b1-d26e62ebc6f9.08c17391d3df289f6842e270f7180eec.jpeg",
"zoomable": true
},
{
"id": "01620E466D3E41A188B92B45D6F48FDA",
"url": "https://i5.walmartimages.com/asr/69c08bf8-207b-4669-81f2-acfa950c4a94.d51028ed9404147f4050401047a6279f.jpeg",
"zoomable": true
},
{
"id": "EEEAAE2BF6914589BC79D558F081EBC2",
"url": "https://i5.walmartimages.com/asr/b3a883cc-c414-4818-a687-de74d04f5349.ad369bba070eb7d13a262d55b1a3980d.jpeg",
"zoomable": true
}
],
"thumbnailUrl": "https://i5.walmartimages.com/seo/Sony-PlayStation-5-PS5-Video-Game-Console_9333b8cd-773e-49d4-8e85-51c4114fcd56.bbf5c4e4f3746ddc28ac982117cdbf9a.jpeg"
},
"name": "Sony PlayStation 5 (PS5) Video Game Console",
"orderMinLimit": 1,
"orderLimit": 1,
"priceInfo": {
"priceDisplayCodes": {
"clearance": null,
"eligibleForAssociateDiscount": null,
"finalCostByWeight": null,
"priceDisplayCondition": null,
"reducedPrice": null,
"rollback": null,
"submapType": null
},
"currentPrice": {
"price": 574.9,
"priceString": "$574.90",
"variantPriceString": "$574.90",
"currencyUnit": "USD",
"bestValue": null,
"priceDisplay": "$574.90"
},
"wasPrice": null,
"comparisonPrice": null,
"unitPrice": null,
"savings": null,
"savingsAmount": null,
"secondaryOfferBoost": "$574.80",
"shipPrice": null,
"isPriceReduced": false,
"priceReducedDisplay": null,
"subscriptionPrice": null,
"priceRange": {
"minPrice": null,
"maxPrice": null,
"priceString": null,
"currencyUnit": null,
"denominations": null
},
"listPrice": null,
"capType": null,
"walmartFundedAmount": null,
"wPlusEarlyAccessPrice": null
},
"type": "Video Game Consoles"
},
"reviews": {
"averageOverallRating": 4.7709,
"aspects": [
{
"id": "2920",
"name": "Graphics",
"score": 96,
"snippetCount": 27
},
....
],
"lookupId": "4S6KN6TWU0A0",
"customerReviews": [
{
"reviewId": "296013686",
"rating": 5,
"reviewSubmissionTime": "12/20/2022",
"reviewText": "The PS5 is awesome! I have had a ps4 for over 4 years and it was time to upgrade. And we’ll it’s totally worth it. Graphics are amazing, the speed on the console is crazy!",
"reviewTitle": "PlayStation did it again! Two thumbs up!",
"negativeFeedback": 3,
"positiveFeedback": 10,
"userNickname": "JohnPaul",
"media": [
{
"id": "60c4edb9-f024-47f5-afe0-09c44dfc4c77",
"reviewId": "720f19d3-257e-5594-bdaa-321bbeaf33dc",
"mediaType": "IMAGE",
"normalUrl": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin",
"thumbnailUrl": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin?odnWidth=150&odnHeight=150&odnBg=ffffff",
"caption": null,
"rating": 5
}
],
"photos": [
{
"caption": null,
"id": "60c4edb9-f024-47f5-afe0-09c44dfc4c77",
"sizes": {
"normal": {
"id": "normal",
"url": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin"
},
"thumbnail": {
"id": "thumbnail",
"url": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin?odnWidth=150&odnHeight=150&odnBg=ffffff"
}
}
}
],
"badges": [
{
"badgeType": "Custom",
"id": "VerifiedPurchaser",
"contentType": "REVIEW",
"glassBadge": {
"id": "VerifiedPurchaser",
"text": "Verified Purchase"
}
}
],
"clientResponses": [],
"syndicationSource": null,
"snippetFromTitle": null
},
....
]
},
"topProductMedia": [
{
"id": "60c4edb9-f024-47f5-afe0-09c44dfc4c77",
"reviewId": "720f19d3-257e-5594-bdaa-321bbeaf33dc",
"mediaType": "IMAGE",
"normalUrl": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin",
"thumbnailUrl": "https://i5.walmartimages.com/dfw/6e29e393-5944/k2-_8d6ff378-f047-4bed-adbe-32a5b1bbba25.v1.bin?odnWidth=150&odnHeight=150&odnBg=ffffff",
"caption": null,
"rating": 5
},
....
],
"totalMediaCount": 62,
"totalReviewCount": 3182
}
}
]We got different data fields about the product, from basic details to pricing, product variation and review data.
Bypass Walmart Scraping Blocking
Walmart has a high blocking rate to protect its product data. So, if we execute our Walmart scraper for many requests, we'll be redirected to blocking or 5 Proven Ways to Bypass CAPTCHA in Python pages.

Walmart is using a complex anti-scraping protection system that analyses the scraper's IP address, HTTP capabilities and JavaScript environment. Meaning that our scraper can easily be identified and blocked if we don't pay attention to these details.
Instead, let's take advantage of ScrapFly API, which can manage these details for us!

ScrapFly offers several powerful features that'll help us to get around Walmart scraping blocking:
- Anti Scraping Protection Bypass - for scraping any website without getting blocked.
- Javascript Rendering - for scraping dynamic loaded content using cloud headless browser.
- 190M Pool of Residential or Mobile Proxies - for avoiding IP throttling and blocking, while also allowing for scraping from any geographical location.
To take advantage of ScrapFly's API in our Walmart web scraper, all we need to do is replace httpx requests with scrapfly-sdk requests:
import httpx
session: httpx.AsyncClient
response = session.get(url)
# replace with scrapfly's SDK:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key='YOUR_SCRAPFLY_KEY')
response = client.scrape(
ScrapeConfig(
url=url,
asp=True, # activate the anti scraping protection to bypass blocking
country="US", # select a specific proxy location
render_js=True # enable JS rendering if needed, similar to headless browsers
))FAQ
Is it legal to scrape Walmart?
Yes. Walmart product data is publicly available. Scraping walmart.com at slow, respectful rates would fall under the ethical scraping definition. See our Is Web Scraping Legal? article for more.
Is there a public API for Walmart?
At the time of writing, Walmart doesn't offer APIs for public use. However, scraping Walmart is straightforward and you can use it to create your own web scraping API.
Are there alternatives for scraping Walamrt?
Yes, refer to our #scrapeguide blog tag for more scraping guides on e-commerce target websites.
Walmart Scraping Summary
In this tutorial, we built a Walmart scraper, which uses search to discover products and then scrapes all the products rapidly while avoiding blocking.
In a nutshell, we have used httpx to request Walmart pages and parsel for parsing the HTML to extract the hidden data under JavaScript tags. Finally, we have used ScrapFly's web scraping API to avoid Walmart scraping blocking.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


