In this tutorial, we'll explain how to write a Google Maps scraper (google.com/maps) - a map service that is also a major directory for business details and reviews.
Google Maps is a complex piece of web software so we'll be using browser automation toolkits like Selenium, Playwright and ScrapFly to render the pages for us in Python. We'll cover all three of these options so feel free to follow along in the one you're most familiar with - let's jump in!
Key Takeaways
Learn to scrape Google Maps business data using Python with browser automation tools for extracting business details, reviews, and contact information from Google's mapping service.
- Use browser automation tools like Selenium or Playwright to handle Google Maps' JavaScript-rendered content with custom wait functions
- Extract business data including names, addresses, phone numbers, and ratings from Google Maps listings using accessibility labels
- Handle Google Maps' dynamic loading and pagination systems for comprehensive data collection with CSS selector waiting
- Implement proper waiting strategies and element detection for reliable data extraction using JavaScript execution
- Use ScrapFly's browser automation features for automated anti-blocking and proxy rotation with country-specific targeting
- Parse structured business information from Google Maps' embedded JSON data and HTML elements using aria-label attributes
Why Scrape Google Maps?
Google Maps contains a vast amount of business profile data like addresses, ratings, phone numbers and website addresses. Scraping Google Maps can provide a robust data directory for business intelligence and market analysis. It can also be used for lead generation as it contains business contact details.
For more on scraping use cases see our extensive web scraping use case article
Project Setup
In this Google Maps web scraping guide, we'll mostly be using Javascript execution feature of browser automation libraries like Selenium, Playwright and ScrapFly's Javascript Rendering feature to retrieve the fully rendered HTML pages.
So, which browser automation library is best for scraping Google Maps?
We only need the rendering and javascript execution capabilities so whichever you're the most comfortable with! That being said, ScrapFly doesn't only provide browser automation context but several powerful features that will help us to get around web scraping blocking like:
- Anti Scraping Protection Bypass - automatically configures browser instances to bypass popular anti web-scraping protection services.
- Vast Pools of Residential or Mobile Proxies - quality IP addresses to help avoid blocking and geo-locked content.
To parse those pages we'll be using parsel - a community package that supports HTML parsing via CSS or XPath selectors.
These packages can be installed through a terminal tool pip:
$ pip install scrapfly-sdk parsel
# for selenium
$ pip install selenium
# for playwright
$ pip install playwrightThe most powerful feature of these tools is javascript execution feature. This feature allows us to send browser any JavaScript code snippet and it will execute it in the context of the current page. Let's take a quick look how can use it in our tools:
JavaScript execution in ScrapFly
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2)
script = 'return document.querySelector("h1").innerHTML' # get first header text
result = scrapfly.scrape(
ScrapeConfig(
url="https://httpbin.dev/html",
# enable javascript rendering for this request and execute a script:
render_js=True,
js=script,
)
)
# results are located in the browser_data field:
title = result.scrape_result['browser_data']['javascript_evaluation_result']
print(title)Javascript Execution in Selenium
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://httpbin.dev/html")
script = 'return document.querySelector("h1").innerHTML' # get first header text
title = driver.execute_script(script)
print(title)Javascript Execution in Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://httpbin.dev/html")
script = 'return document.querySelector("h1").innerHTML' # get first header text
title = page.evaluate("() => {" + script + "}")
print(title)Javascript execution is the key feature of all browser automation tools, so let's take a look at how can we use it to scrape Google Maps!
How to Find Google Maps Places
To find places on Google Maps we'll take advantage of the search system. Maps being a Google product has a great search system that can understand natural language queries.
For example, if we want to find the page for Louvre Museum in Paris we can use an accurate human-like search query: Louvre Museum in Paris. Which can be submitted directly through the URL endpoint /maps/search/louvr+paris:
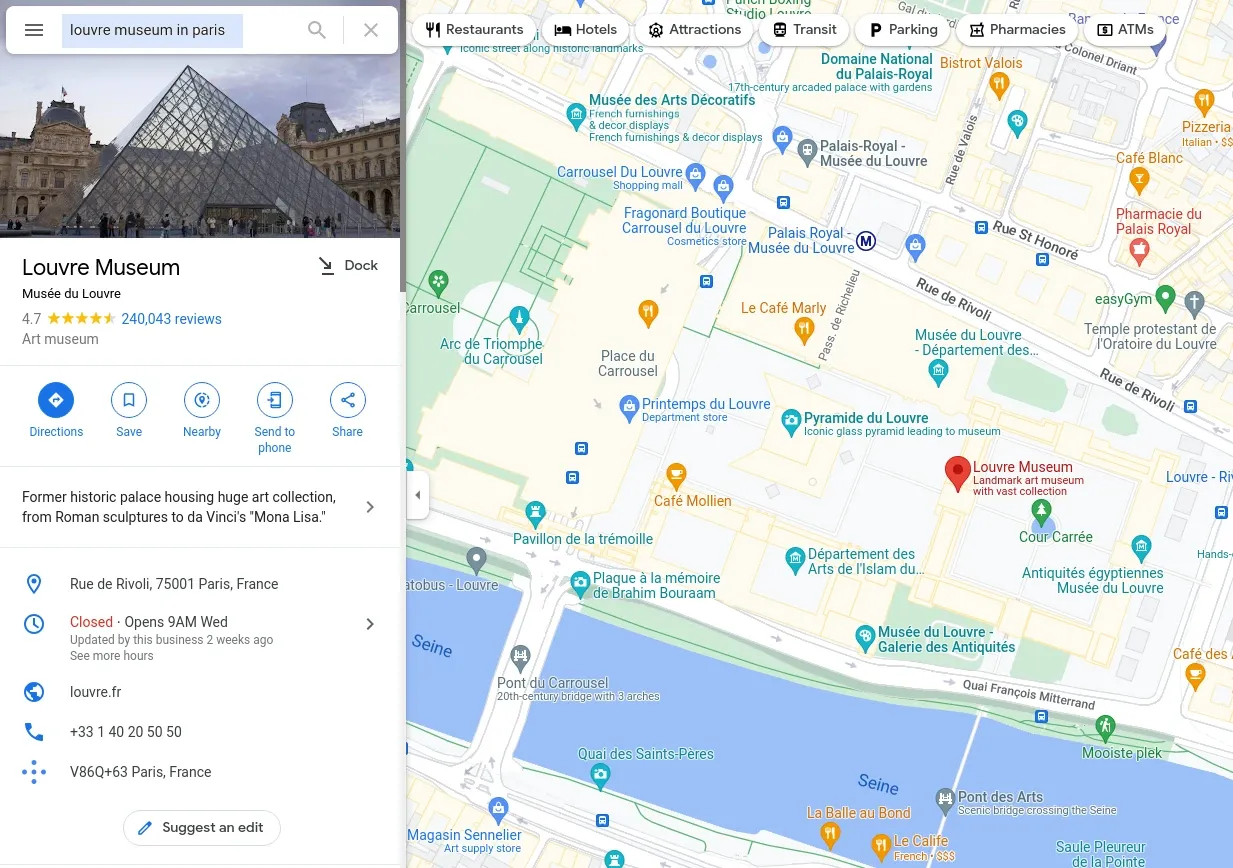
On the other hand, for less accurate search queries like /maps/search/mcdonalds+in+paris will provide multiple results to choose from:
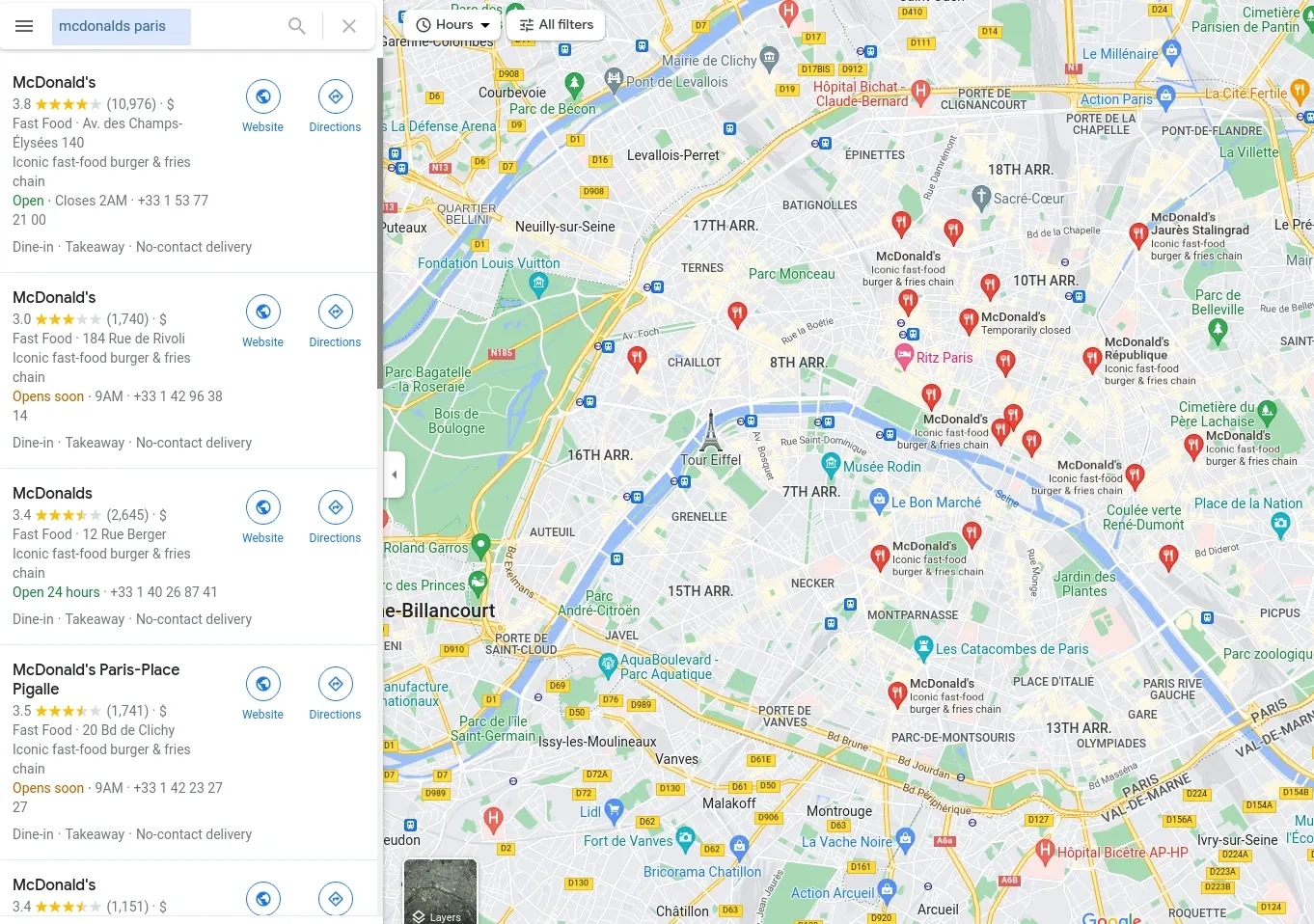
We can see that this powerful endpoint can either take us directly to the place page or show us multiple results. To start, let's take a look at the latter - how to scrape Google Maps search results.
Now that we know how to generate the search URL all we need to do is open it up, wait for it to load and extract the links. As we'll be working with highly dynamic web pages we need a helper function that will help us ensure the content has loaded:
// Wait for N amount of selectors to be present in the DOM
function waitCss(selector, n=1, require=false, timeout=5000) {
console.log(selector, n, require, timeout);
var start = Date.now();
while (Date.now() - start < timeout){
if (document.querySelectorAll(selector).length >= n){
return document.querySelectorAll(selector);
}
}
if (require){
throw new Error(`selector "${selector}" timed out in ${Date.now() - start} ms`);
} else {
return document.querySelectorAll(selector);
}
}With this utility function, we'll be able to make sure our scraping script waits for the content to load before starting to parse it.
Let's put it to use in our search scraper:
Using ScrapFly
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2)
script = """
function waitCss(selector, n=1, require=false, timeout=5000) {
console.log(selector, n, require, timeout);
var start = Date.now();
while (Date.now() - start < timeout){
if (document.querySelectorAll(selector).length >= n){
return document.querySelectorAll(selector);
}
}
if (require){
throw new Error(`selector "${selector}" timed out in ${Date.now() - start} ms`);
} else {
return document.querySelectorAll(selector);
}
}
var results = waitCss("div.Nv2PK a, div.tH5CWc a, div.THOPZb a", n=10, require=false);
return Array.from(results).map((el) => el.getAttribute("href"))
"""
def search(query):
result = scrapfly.scrape(
ScrapeConfig(
url=f"https://www.google.com/maps/search/{query.replace(" ", "+")}/?hl=en",
render_js=True,
js=script,
country="US",
)
)
urls = result.scrape_result['browser_data']['javascript_evaluation_result']
return urls
print(search("museum in paris"))
print(search("mcdonalds in paris"))Using Selenium
from selenium import webdriver
script = """
function waitCss(selector, n=1, require=false, timeout=5000) {
console.log(selector, n, require, timeout);
var start = Date.now();
while (Date.now() - start < timeout){
if (document.querySelectorAll(selector).length >= n){
return document.querySelectorAll(selector);
}
}
if (require){
throw new Error(`selector "${selector}" timed out in ${Date.now() - start} ms`);
} else {
return document.querySelectorAll(selector);
}
}
var results = waitCss("div.Nv2PK a, div.tH5CWc a, div.THOPZb a", n=10, require=false);
return Array.from(results).map((el) => el.getAttribute("href"))
"""
driver = webdriver.Chrome()
def search(query):
url = f"https://www.google.com/maps/search/{query.replace(' ', '+')}/?hl=en"
driver.get(url)
urls = driver.execute_script(script)
return urls or [url]
print(f'single search: {search("museum in paris")}')
print(f'multi search: {search("mcdonalds in paris")}')
Using Playwright
from playwright.sync_api import sync_playwright
script = """
function waitCss(selector, n=1, require=false, timeout=5000) {
console.log(selector, n, require, timeout);
var start = Date.now();
while (Date.now() - start < timeout){
if (document.querySelectorAll(selector).length >= n){
return document.querySelectorAll(selector);
}
}
if (require){
throw new Error(`selector "${selector}" timed out in ${Date.now() - start} ms`);
} else {
return document.querySelectorAll(selector);
}
}
var results = waitCss("div.Nv2PK a, div.tH5CWc a, div.THOPZb a", n=10, require=false);
return Array.from(results).map((el) => el.getAttribute("href"))
"""
def search(query, page):
url = f"https://www.google.com/maps/search/{query.replace(' ', '+')}/?hl=en"
page.goto(url)
urls = page.evaluate("() => {" + script + "}")
return urls or [url]
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
print(f'single search: {search("museum in paris", page=page)}')
print(f'multi search: {search("mcdonalds in paris", page=page)}')
Results
single search: ['https://www.google.com/maps/search/louvre+museum+in+paris/?hl=en']
multi search: [
"https://www.google.com/maps/place/McDonald's/data=!4m7!3m6!1s0x47e66fea26bafdc7:0x21ea7aaf1fb2b3e3!8m2!3d48.8729997!4d2.2991604!16s%2Fg%2F1hd_88rdh!19sChIJx_26Jupv5kcR47OyH6966iE?authuser=0&hl=en&rclk=1",
...
]Our Google Maps scraper can successfully find places on google maps. Let's take a look at how can we scrape their data.
How to Scrape Google Maps Places
To scrape place data, we'll use the same approach of rendering JavaScript content using browser automation. To do that, we'll take the company URLs we discovered previously and scrape the overview data of each company.
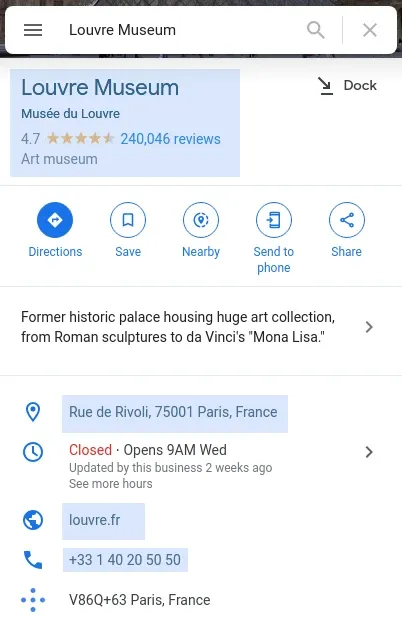
To parse the rendered HTML data we'll be using parsel with a few simple CSS selectors:
def parse_place(selector):
"""parse Google Maps place"""
def aria_with_label(label):
"""gets aria element as is"""
return selector.css(f"*[aria-label*='{label}']::attr(aria-label)")
def aria_no_label(label):
"""gets aria element as text with label stripped off"""
text = aria_with_label(label).get("")
return text.split(label, 1)[1].strip()
result = {
"name": "".join(selector.css("h1 ::text").getall()).strip(),
"category": selector.xpath(
"//button[contains(@jsaction, 'category')]/text()"
).get(),
# most of the data can be extracted through accessibility labels:
"address": aria_no_label("Address: "),
"website": aria_no_label("Website: "),
"phone": aria_no_label("Phone: "),
"review_count": aria_with_label(" reviews").get(),
# to extract star numbers from text we can use regex pattern for numbers: "\d+"
"stars": aria_with_label(" stars").re("\d+.*\d+")[0],
"5_stars": aria_with_label("5 stars").re(r"(\d+) review")[0],
"4_stars": aria_with_label("4 stars").re(r"(\d+) review")[0],
"3_stars": aria_with_label("3 stars").re(r"(\d+) review")[0],
"2_stars": aria_with_label("2 stars").re(r"(\d+) review")[0],
"1_stars": aria_with_label("1 stars").re(r"(\d+) review")[0],
}
return resultSince google maps is using complex HTML structures and CSS styles so parsing it can be very difficult. Fortunately, google maps also implement vast accessibility features which we can take advantage of!
Let's add this to our Google Maps scraper:
🙋 The following script heavily relis on matching againist the HTML text, make sure you are setting the language to English while running the Playwright code. For more details, see our previous guide - how to set web scraping language.
Using ScrapFly
import json
from scrapfly import ScrapflyClient, ScrapeConfig
urls = ["https://goo.gl/maps/Zqzfq43hrRPmWGVB7"]
def parse_place(selector):
"""parse Google Maps place"""
def aria_with_label(label):
"""gets aria element as is"""
return selector.css(f"*[aria-label*='{label}']::attr(aria-label)")
def aria_no_label(label):
"""gets aria element as text with label stripped off"""
text = aria_with_label(label).get("")
return text.split(label, 1)[1].strip()
result = {
"name": "".join(selector.css("h1 ::text").getall()).strip(),
"category": selector.xpath(
"//button[contains(@jsaction, 'category')]/text()"
).get(),
# most of the data can be extracted through accessibility labels:
"address": aria_no_label("Address: "),
"website": aria_no_label("Website: "),
"phone": aria_no_label("Phone: "),
"review_count": aria_with_label(" reviews").get(),
# to extract star numbers from text we can use regex pattern for numbers: "\d+"
"stars": aria_with_label(" stars").re("\d+.*\d+")[0],
"5_stars": aria_with_label("5 stars").re(r"(\d+) review")[0],
"4_stars": aria_with_label("4 stars").re(r"(\d+) review")[0],
"3_stars": aria_with_label("3 stars").re(r"(\d+) review")[0],
"2_stars": aria_with_label("2 stars").re(r"(\d+) review")[0],
"1_stars": aria_with_label("1 stars").re(r"(\d+) review")[0],
}
return result
scrapfly = ScrapflyClient(key="Your ScrapFly API key", max_concurrency=2)
places = []
for url in urls:
result = scrapfly.scrape(
ScrapeConfig(
url=url,
render_js=True,
# set the proxy country to the US while also rendering the HTML text in English
country="US",
wait_for_selector="//button[contains(@jsaction, 'reviewlegaldisclosure')]"
)
)
places.append(parse_place(result.selector))
print(json.dumps(places, indent=2, ensure_ascii=False))Using Playwright
import json
from parsel import Selector
from playwright.sync_api import sync_playwright
def parse_place(selector):
"""parse Google Maps place"""
def aria_with_label(label):
"""gets aria element as is"""
return selector.css(f"*[aria-label*='{label}']::attr(aria-label)")
def aria_no_label(label):
"""gets aria element as text with label stripped off"""
text = aria_with_label(label).get("")
return text.split(label, 1)[1].strip()
result = {
"name": "".join(selector.css("h1 ::text").getall()).strip(),
"category": selector.xpath(
"//button[contains(@jsaction, 'category')]/text()"
).get(),
# most of the data can be extracted through accessibility labels:
"address": aria_no_label("Address: "),
"website": aria_no_label("Website: "),
"phone": aria_no_label("Phone: "),
"review_count": aria_with_label(" reviews").get(),
# to extract star numbers from text we can use regex pattern for numbers: "\d+"
"stars": aria_with_label(" stars").re("\d+.*\d+")[0],
"5_stars": aria_with_label("5 stars").re(r"(\d+) review")[0],
"4_stars": aria_with_label("4 stars").re(r"(\d+) review")[0],
"3_stars": aria_with_label("3 stars").re(r"(\d+) review")[0],
"2_stars": aria_with_label("2 stars").re(r"(\d+) review")[0],
"1_stars": aria_with_label("1 stars").re(r"(\d+) review")[0],
}
return result
urls = ["https://goo.gl/maps/Zqzfq43hrRPmWGVB7?hl=en"]
places = []
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
# add accept langauge header to display the HTML content in English
context.set_extra_http_headers({
"Accept-Language": "en-US,en;q=0.5",
})
page = context.new_page()
for url in urls:
page.goto(url)
page.wait_for_selector("//button[contains(@jsaction, 'reviewlegaldisclosure')]")
places.append(parse_place(Selector(text=page.content())))
print(json.dumps(places, indent=2, ensure_ascii=False))Results
[
{
"name": "Louvre Museum",
"category": "Art museum",
"address": "Rue de Rivoli, 75001 Paris, France",
"website": "louvre.fr",
"phone": "+33 1 40 20 50 50",
"review_count": "240,040 reviews",
"stars": "4.7",
"5_stars": "513",
"4_stars": "211",
"3_stars": "561",
"2_stars": "984",
"1_stars": "771"
}
]We can see that just with a few lines of clever code we can scrape Google Maps for business. We focused on a few visible details but there's more information available in the HTML body like reviews, news articles and various classification tags.
FAQ
Is it legal to scrape Google Maps?
Yes. Google Maps data is publicly available, and we're not extracting anything private. Scraping Google Maps at slow, respectful rates would fall under the ethical scraping definition. That being said, attention should be paid to GDRP compliance in the EU when scraping personal data such as details attached to the reviews (images or names). For more, see our Is Web Scraping Legal? article.
How to change Google Maps display language?
To change the language of the content displayed on Google Maps we can use URL parameter hl (stands for "Human Language"). For example, for English we would add ?hl=en to the end of our URL. For more details, refer to our previous guide - how to change web scraping language.
Web Scraping Google Maps Summary
In this tutorial, we built a Google Maps scraper that can be used in Selenium, Playwright or ScrapFly's SDK. We did this by launching a browser instance and controlling it via Python code to find businesses through Google Maps search and scrape the details like website, phone number and meta information of each business.
For this, we used Python with a few community packages included in the scrapfly-sdk and to prevent being blocked we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more on ScrapFly see our documentation and try it out for free!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.