

SERP is a common industry term used in the SEO and brand awareness areas, representing each search result's ranking. But what about scraping them from Google search pages?
Web scraping Google search can be difficult as Google uses a lot of obfuscation and anti-scraping technologies, requiring us to dive into several technical points like URL formatting, dynamic HTML parsing and avoiding scraping blocking. In 2026, Google's SERP layout continues to evolve with AI-generated overviews and rich snippets, making robust HTML parsing more important than ever.
In this article, we'll explain how to scrape Google search results using Python. We'll be looking at scraping with Python using traditional tools such as HTTP clients and HTML parsers, as well as ScrapFly-SDK. Let's dive in!
Key Takeaways
Master Google search scraping with Python using httpx and parsel, handling dynamic SERP content and bypassing anti-bot measures through proper request formatting.
- Reverse engineer Google's search URL parameters to construct queries and navigate pagination
- Parse dynamic HTML using XPath selectors to extract search result data from SERPs
- Bypass Google's JavaScript challenges and anti-scraping measures with proper headers
- Extract structured data including titles, URLs, snippets, and ranking information
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use ScrapFly SDK for automated bypassing of Google's bot detection systems
Why Scrape Google Search?
Google search is arguably the most extensive public database on the internet, and it's a great data source for many use cases. Google indexes most of the public web pages, so scraping Google search allows us access to numerous data insights.
Another popular use case is SEO (Search Engine Optimization), where businesses can scrape Google search to know what keywords competitors use and how they rank, allowing for better market acquisition. Complementing SERP data with website traffic analytics from SimilarWeb provides deeper competitive intelligence including visitor demographics, traffic sources, and engagement metrics.
Google search also features a snippets system that summarizes data from popular sources like IMDb, Wikipedia, etc. Google search scraping can be used to scrape these data directly from the search pages.
Project Setup
In this tutorial we'll be scraping Google search using Python with a few popular community packages:
- httpx as our HTTP client which we'll use to retrieve search results HTMLs.
- parsel as our HTML parser. Since Google uses a lot of dynamic HTML we'll be using some clever XPath selectors to find the result data.
There are many popular alternatives to these two packages like beautifulsoup is a popular alternative to parsel, however since Google pages can be difficult to parse we'll be using parsel's XPath selectors which are much more powerful than CSS selectors used by beautifulsoup.
For the HTTP client we chose httpx as it's capable of HTTP/2 which helps to avoid blocking. Though using other clients like requests or aiohttp is also possible.
🤖 Google is notorious for blocking web scraping so to follow along make sure to space out your requests to a few requests per minute to avoid being blocked. See the blocking section for more.
Alternatively, this blog also provides code using ScrapFly SDK which solves many of the problems we'll be discussing in this tutorial automatically.
How to Scrape Google Search Results
Let's start Google search scraping by taking a look at what happens when we input the query "scrapfly blog" in the Google search.
We can see that once we input the query we are taken to the search results URL that looks like google.com/search?hl=en&q=scrapfly%20blog.
So, the search is using the /search endpoint and the query is being passed as a q parameter. The hl parameter is the language code and we can see that it's set to en which means English.
This URL will get us the page but how do we parse it for the search results? For that, we'll be using XPath selectors and since Google uses dynamic HTML we'll follow the heading elements:

While Google uses dynamic HTML we can still rely on relative structure for scraping. We can select <h3> elements and treat them as containers for each search result. Let's try it out:
from collections import defaultdict
from urllib.parse import quote
from httpx import Client
from parsel import Selector
# 1. Create HTTP client with headers that look like a real web browser
client = Client(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
http2=True, # use HTTP/2
)
def parse_search_results(selector: Selector):
"""parse search results from google search page"""
results = []
for box in selector.xpath("//h1[contains(text(),'Search Results')]/following-sibling::div[1]/div"):
title = box.xpath(".//h3/text()").get()
url = box.xpath(".//h3/../@href").get()
text = "".join(box.xpath(".//div[@data-sncf]//text()").getall())
if not title or not url:
continue
url = url.split("://")[1].replace("www.", "")
results.append(title, url, text)
return results
def scrape_search(query: str, page=1):
"""scrape search results for a given keyword"""
# retrieve the SERP
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
response = client.get(url)
assert response.status_code == 200, f"failed status_code={response.status_code}"
# parse SERP for search result data
selector = Selector(response.text)
results["search"].extend(parse_search_results(selector))
return dict(results)
# example use: scrape 3 pages: 1,2,3
for page in [1, 2, 3]:
results = scrape_search("scrapfly blog", page=page)
for result in results["search"]:
print(result)from collections import defaultdict
from urllib.parse import quote
from parsel import Selector
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient("YOUR SCRAPFLY KEY")
def parse_search_results(selector: Selector):
"""parse search results from google search page"""
results = []
for box in selector.xpath("//h1[contains(text(),'Search Results')]/following-sibling::div[1]/div"):
title = box.xpath(".//h3/text()").get()
url = box.xpath(".//h3/../@href").get()
text = "".join(box.xpath(".//div[@data-sncf]//text()").getall())
if not title or not url:
continue
url = url.split("://")[1].replace("www.", "")
results.append((title, url, text))
return results
def scrape_search(query: str, page=1, country="US"):
"""scrape search results for a given keyword"""
# retrieve the SERP
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
result = scrapfly.scrape(ScrapeConfig(url, country=country, asp=True))
# parse SERP for search result data
results["search"].extend(parse_search_results(result.selector))
return dict(results)
# Example use: scrape 3 pages: 1,2,3
for page in [1, 2, 3]:
results = scrape_search("scrapfly blog", page=page)
for result in results["search"]:
print(result)Example Output
('Blog - ScrapFly', 'scrapfly.io/blog/', 'Scrapfly - Web Scraping API - Headless browser. Blog on everything web scraping: tutorials, guides, highlights and industry observations.Complete web scraping tutorials for specific web scraping targets like yelp.com,\xa0...')
('Scrapecrow', 'scrapecrow.com/', 'Educational blog about web-scraping, crawling and related data extraction ... a year of professional web scraping blogging at ScrapFly and my key takeaways.')
('Scrapfly Web Scraping API free alternatives service', 'freestuff.dev/alternative/scrapfly-web-scraping-api/', 'Scrapfly is a Web Scraping API providing residential proxies, headless browser to extract data and bypass captcha / anti bot vendors. Tag: scraping, crawling.')
('Scrapfly | Software Reviews & Alternatives - Crozdesk', 'crozdesk.com/software/scrapfly', "Scrapfly Review: 'Simple but powerful Web Scraping API - We provide fully managed web scraping through a simple REST API.'")
('Issues · scrapfly/python-scrapfly - GitHub', 'github.com/scrapfly/python-scrapfly/issues', 'Scrapfly Python SDK for headless browsers and proxy rotation - Issues · scrapfly/python-scrapfly.install: python -m pip install --user --upgrade setuptools wheel. python -m pip install --user --upgrade twine pdoc3 colorama. bump: sed -i "1s/.')
('Web scraping with Python open knowledge | Hacker News', 'news.ycombinator.com/item?id=31531694', 'I recently joined a brilliant web scraping API company called ScrapFly, who provided me with the ... 1 - https://scrapfly.io/blog/parsing-html-with-xpath/.')
('Scrapfly API and Tiktok Unofficial API integrations - Meta API', 'dashboard.meta-api.io/apis/scrapfly/integrations/tiktok-unofficial', 'Connect Scrapfly & Tiktok Unofficial to sync data between apps and create easy to maintain APIs integrations without losing control.')
('Scrapfly - Crunchbase Company Profile & Funding', 'crunchbase.com/organization/scrapfly', 'Contact Email contact@scrapfly.io. Simple but powerful Web Scraping API - We provide fully managed web scraping through a simple REST API.')
...In the example above we wrote a short google search scraper. We first created a httpx client with headers that imitate a web browser to prevent being blocked by Google, then we defined two functions:
parse_search_results, which parses search results from a given SERP. Note that for parsing we use XPath selectors that use heading text matching instead of usual class or id matching. This is because Google uses dynamic HTML and we can't rely on static class names.
scrape_search, which takes a query and page number and returns a list of search results. We can use this function to scrape google results of a given query. So, let's take it for a spin and do some SEO analytics next!
How to Scrape Google SEO Rankings
Now that we can scrape SERP let's take a look at how we can use this data in SEO practices.

To start, we can use this data to determine our position in search results for given queries or keywords. For example, let's say we want to see how well our blog post about web scraping instagram is ranking for the keyword/query "scrape instagram":
import re
def check_ranking(keyword: str, url_match: str, max_pages=3):
"""check ranking of a given url (partial) for a given keyword"""
rank = 1
for page in range(1, max_pages + 1):
results = scrape_search(keyword, page=page)
for (title, result_url, text) in results["search"]:
if url_match in result_url:
print(f"rank found:\n {title}\n {text}\n {result_url}")
return rank
rank += 1
return None
check_ranking(
keyword="scraping instagram",
url_match="scrapfly.com/blog/",
)import re
def check_ranking(keyword: str, url_match: str, max_pages=3, country="US"):
"""check ranking of a given url (partial) for a given keyword"""
rank = 1
for page in range(1, max_pages + 1):
results = scrape_search(keyword, page=page, country=country)
for (title, result_url, text) in results["search"]:
if url_match in result_url:
print(f"rank found:\n {title}\n {text}\n {result_url}")
return rank
rank += 1
return None
check_ranking(
keyword="scraping instagram",
url_match="scrapfly.com/blog/",
country="US",
)Above, we used our previously defined Google search scraper (the scrape_search function) to collect search result data from SERPs until we encounter our blog post. In real life, we would run this Google scraper once in a while to collect our search engine performance. We can also use this data to confirm that search result titles and descriptions appear as we want them to and adjust our content accordingly.
How to Scrape Google Keyword Data
A big part of SEO is keyword research - understanding what people are searching for and how to optimize content based on these queries.
When it comes to Google search scraping, the "People Also Ask" and "Related Searches" sections can be used in keyword research:
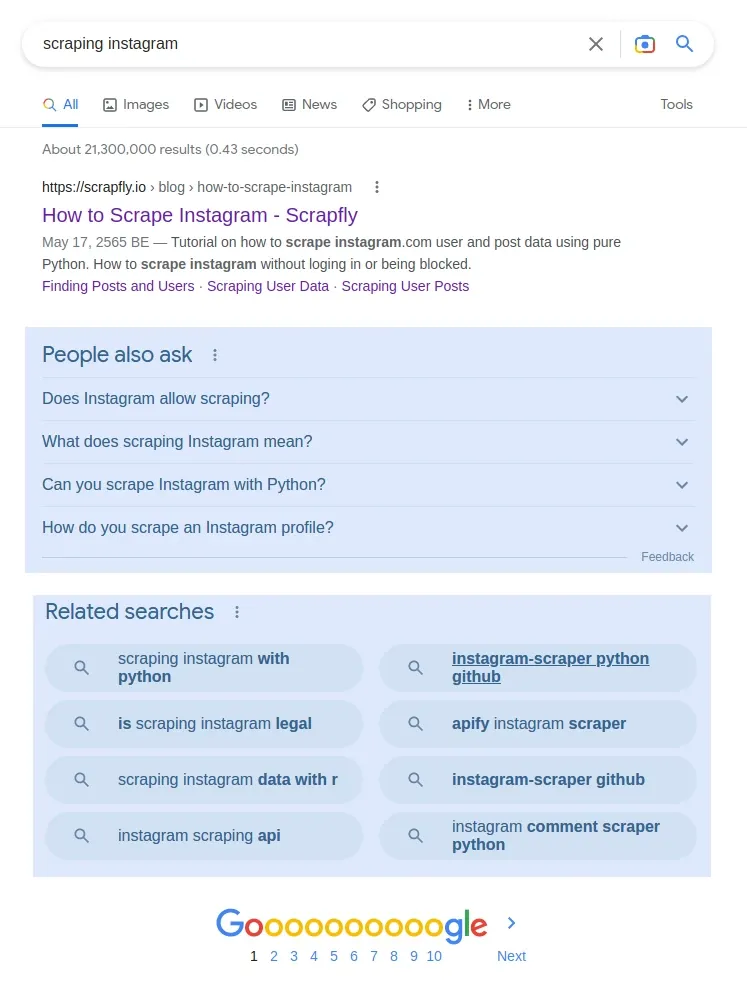
Let's take a look at how we can scrape Google search to get the above sections by continuing with our research for web scraping instagram article:
from collections import defaultdict
import json
from urllib.parse import quote
from httpx import Client
from parsel import Selector
# 1. Create HTTP client with headers that look like a real web browser
client = Client(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
http2=True,
)
def parse_related_search(selector: Selector):
"""get related search keywords of current SERP"""
results = []
for suggestion in selector.xpath(
"//div[div/div/span[contains(text(), 'search for')]]/following-sibling::div//a"
):
results.append("".join(suggestion.xpath(".//text()").getall()))
return results
def parse_people_also_ask(selector: Selector):
"""get people also ask questions of current SERP"""
return selector.css(".related-question-pair span::text").getall()
def scrape_search(query: str, page=1):
"""scrape search results for a given keyword"""
# retrieve the SERP
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
response = client.get(url)
assert response.status_code == 200, f"failed status_code={response.status_code}"
# parse SERP for search result data
selector = Selector(response.text)
results["related_search"].extend(parse_related_search(selector))
results["people_also_ask"].extend(parse_people_also_ask(selector))
return dict(results)
# Example use:
results = scrape_search("scraping instagram")
print(json.dumps(results, indent=2))from collections import defaultdict
import json
from urllib.parse import quote
from parsel import Selector
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient("YOUR SCRAPFLY KEY")
def parse_related_search(selector: Selector):
"""get related search keywords of current SERP"""
results = []
for suggestion in selector.xpath(
"//div[div/div/span[contains(text(), 'search for')]]/following-sibling::div//a"
):
results.append("".join(suggestion.xpath(".//text()").getall()))
return results
def parse_people_also_ask(selector: Selector):
"""get people also ask questions of current SERP"""
return selector.css(".related-question-pair span::text").getall()
def scrape_search(query: str, page=1, country="US"):
"""scrape search results for a given keyword"""
# retrieve the SERP
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
result = scrapfly.scrape(ScrapeConfig(url, country=country, asp=True))
# parse SERP for search result data
results["related_search"].extend(parse_related_search(result.selector))
results["people_also_ask"].extend(parse_people_also_ask(result.selector))
return dict(results)
# Example use:
results = scrape_search("scraping instagram", country="US")
print(json.dumps(results, indent=2))Example Output
{
"related_search": [
"scraping instagram with python",
"is scraping instagram legal",
"instagram scraping api",
"scraping instagram data with r",
"instagram-scraper python github",
"instagram comment scraper python",
"instagram scraper free",
"instagram-scraper github"
],
"people_also_ask": [
"Does Instagram allow scraping?",
"What does scraping Instagram mean?",
"How do you scrape an Instagram account?",
"Can you scrape Instagram with Python?"
]
}Above, we defined two functions to parse related searches and related questions which we can use in SEO keyword research.
How to Scrape Google Rich Results
Google also offers rich results in the form of snippets. These are summaries of popular data sources like Wikipedia, IMDb, etc. For example, here is the Google snippet:
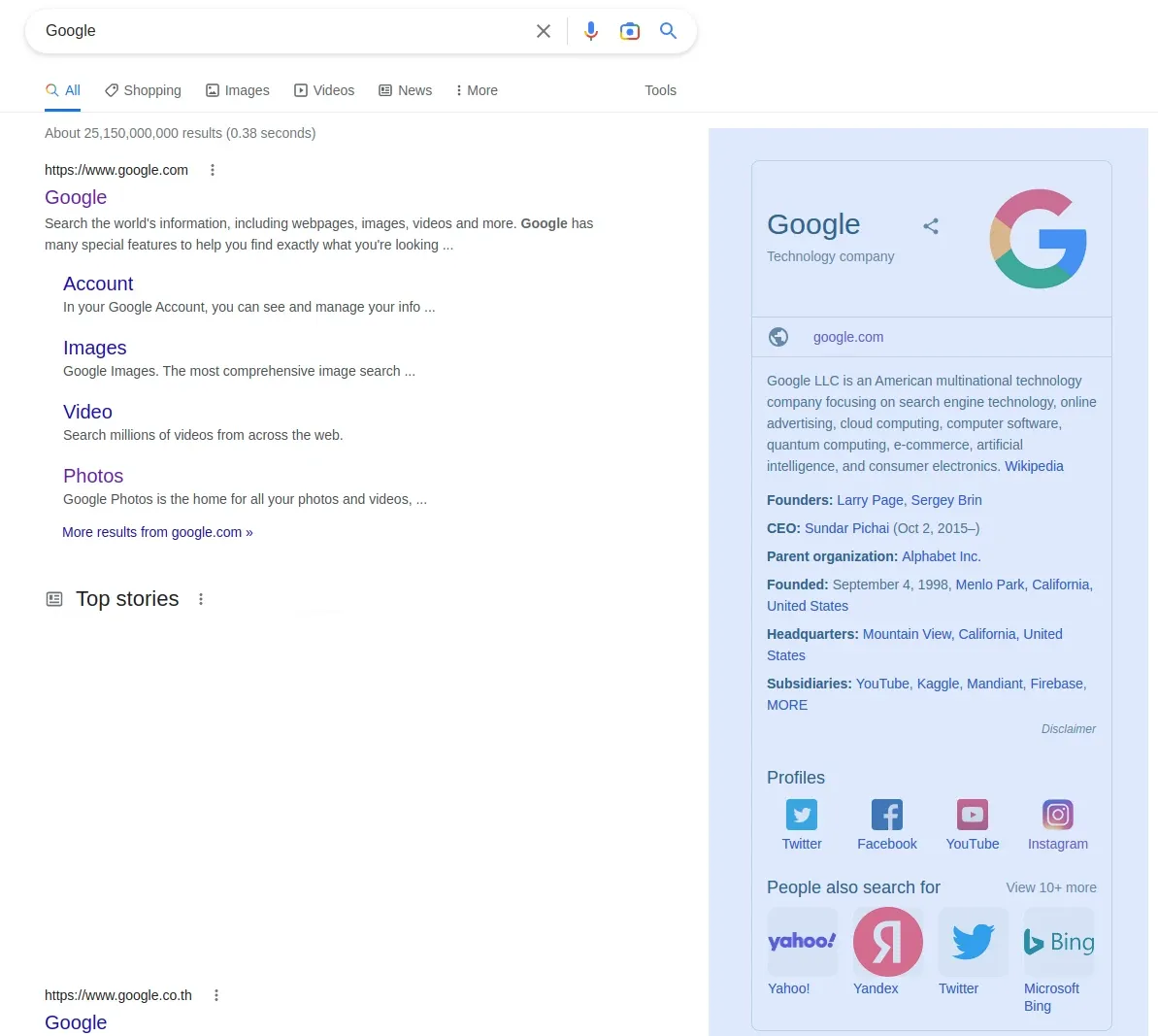
Snippet can aggregate data from multiple sources in a concise, predictable format so it's a popular web scraping target as we can easily gather information about popular targets like companies, public figures and bodies of work. Here is how we can web scrape Google snippets:
from parsel import Selector
from httpx import Client
client = Client(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
)
def parse_search_snippet(selector: Selector):
snippet = selector.xpath("//h2[re:test(.,'complementary results','i')]/following-sibling::div[1]")
data = {
"title": snippet.xpath(".//*[@data-attrid='title']//text()").get(),
"subtitle": snippet.xpath(".//*[@data-attrid='subtitle']//text()").get(),
"website": snippet.xpath(".//a[@data-attrid='visit_official_site']/@href").get(),
"description": snippet.xpath(".//div[@data-attrid='description']//span//text()").get(),
"description_more_link": snippet.xpath(".//div[@data-attrid='description']//@href").get(),
}
# get summary info rows
data["info"] = {}
for row in snippet.xpath(".//div[@data-md]/div/div/div[span]"):
label = row.xpath(".//span/text()").get()
value = row.xpath(".//a/text()").get()
data["info"][label] = value
# get social media links
data["socials"] = {}
for profile in snippet.xpath(".//div[@data-attrid='kc:/common/topic:social media presence']//g-link/a"):
label = profile.xpath(".//text()").get()
url = profile.xpath(".//@href").get()
data["socials"][label] = url
return data
def scrape_search(query: str, page=1):
"""scrape search results for a given keyword"""
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
response = client.get(url)
assert response.status_code == 200, f"failed status_code={response.status_code}"
selector = Selector(response.text)
results["search"].extend(parse_search_results(selector))
results["rich_snippets"] = parse_search_snippet(selector)
return dict(results)
# example:
print(scrape_search("google")["rich_snippets"])from collections import defaultdict
from urllib.parse import quote
from parsel import Selector
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="YOUR SCRAPFLY API KEY")
def parse_search_snippet(selector: Selector):
"""parse rich snippet data from google SERP"""
snippet = selector.xpath("//h2[re:test(.,'complementary results','i')]/following-sibling::div[1]")
data = {
"title": snippet.xpath(".//*[@data-attrid='title']//text()").get(),
"subtitle": snippet.xpath(".//*[@data-attrid='subtitle']//text()").get(),
"website": snippet.xpath(".//a[@data-attrid='visit_official_site']/@href").get(),
"description": snippet.xpath(".//div[@data-attrid='description']//span//text()").get(),
"description_more_link": snippet.xpath(".//div[@data-attrid='description']//@href").get(),
}
# get summary info rows
data["info"] = {}
for row in snippet.xpath(".//div[@data-md]/div/div/div[span]"):
label = row.xpath(".//span/text()").get()
value = row.xpath(".//a/text()").get()
data["info"][label] = value
# get social media links
data["socials"] = {}
for profile in snippet.xpath(".//div[@data-attrid='kc:/common/topic:social media presence']//g-link/a"):
label = profile.xpath(".//text()").get()
url = profile.xpath(".//@href").get()
data["socials"][label] = url
return data
def scrape_search(query: str, page=1, country="US"):
"""scrape search results for a given keyword and country"""
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
result = scrapfly.scrape(ScrapeConfig(url=url, country=country, asp=True))
results["rich_snippets"] = parse_search_snippet(result.selector)
return dict(results)
# example:
print(scrape_search("google", country="US")["rich_snippets"])Example Output
{
"title": "Google",
"subtitle": "Technology company",
"website": "http://www.google.com/",
"description": "Google LLC is an American multinational technology company focusing on search engine technology, online advertising, cloud computing, computer software, quantum computing, e-commerce, artificial intelligence, and consumer electronics.",
"description_more_link": "https://en.wikipedia.org/wiki/Google",
"info": {
"founders": "Larry Page, Sergey Brin",
"ceo": "Sundar Pichai (Oct 2, 2015\u2013)",
"parent organization": "Alphabet Inc.",
"founded": "September 4, 1998, Menlo Park, CA",
"headquarters": "Mountain View, CA",
"subsidiaries": "YouTube, Kaggle, Mandiant, Firebase, MORE"
},
"socials": {
"Twitter": "https://twitter.com/Google",
"Facebook": "https://www.facebook.com/Google",
"LinkedIn": "https://www.linkedin.com/company/google",
"YouTube": "https://www.youtube.com/c/google",
"Instagram": "https://www.instagram.com/google"
}
}In this example, we collected details from the rich company overview snippet. For parsing this we relied on headings and data- attributes which can be reliably used to parse dynamic HTML documents. Note that rich snippets vary highly depending on subject and in our example we only cover one kind of rich snippet. However, most of the scraping logic can be reused for other details.
Google offers many different kinds of rich snippets and they can be scraped in a similar way.
Bypass Google Search Web Scraping Blocking
Our previous scripts can web scrape Google well. However, we have two problems:
- We have no way to specify search results for a specific country.
- If we scale them up Google will start blocking us.
Unfortunately, the only way to see results of a specific country is to use a proxy IP address or a web scraping API like ScrapFly.
ScrapFly acts a middleware between your scraper and your target automatically retrieving hard to reach content for you. It does this by employing millions of different proxies and smart request routing. So, we can solve both problems by using ScrapFly.

To scrape Google search using Scrapfly, we'll only have to replace our HTTP client with ScrapFly-SDK:
from collections import defaultdict
from urllib.parse import quote
from parsel import Selector
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient("YOUR SCRAPFLY KEY")
def parse_search_results(selector: Selector):
"""parse search results from google search page"""
results = []
for box in selector.xpath("//h1[contains(text(),'Search Results')]/following-sibling::div[1]/div"):
title = box.xpath(".//h3/text()").get()
url = box.xpath(".//h3/../@href").get()
text = "".join(box.xpath(".//div[@data-content-feature=1]//text()").getall())
if not title or not url:
continue
url = url.split("://")[1].replace("www.", "")
results.append((title, url, text))
return results
def scrape_search(query: str, page=1, country="US"):
"""scrape search results for a given keyword"""
# retrieve the SERP
url = f"https://www.google.com/search?hl=en&q={quote(query)}" + (f"&start={10*(page-1)}" if page > 1 else "")
print(f"scraping {query=} {page=}")
results = defaultdict(list)
result = scrapfly.scrape(ScrapeConfig(url, country=country, asp=True))
# parse SERP for search result data
results["search"].extend(parse_search_results(result.selector))
return dict(results)
# Example use: scrape 3 pages: 1,2,3
for page in [1, 2, 3]:
results = scrape_search("scrapfly blog", page=page)
for result in results["search"]:
print(result)By replacing httpx client with scrapfly SDK, we don't have to worry about Google search scraping blocking and get the results for a specific country.
FAQ
Is Google search scraping legal?
Yes, it is perfectly legal to scrape Google search results as it's public, non-copyrighted data. However, attention should be paid to copyrighted images and videos which might be included in search results.
Is there a Google search API?
No, there is no official Google search API. However, scraping Google search is straightforward and you can use it to create your own web scraping API.
How to scrape Google Maps?
Google Maps is a separate service and can be scraped in a similar way as Google search results. For that see our tutorial on How to scrape google maps.
What are alternatives to scraping Google Search?
Bing is the second most popular search engine and a great alternative for SERP data collection. We have a detailed guide on scraping Bing Search with Python. Many other search engines like DuckDuckGo and Kagi use Bing's data, so scraping Bing can provide coverage for these search engines as well.
How to Web Scrape Google Search - Summary
In this tutorial, we wrote a Google search web scraper using Python with a few community packages. For retrieving the SERP content we used httpx which supports http2 and asynchronous connections and to parse the data we used parsel with XPath selectors to extract data from dynamic HTML pages.
The biggest Google scraping challenges can be split into two categories:
- Parsing complex HTML pages.
For that, we used XPath selectors and focused on HTML structures like heading elements and CSSdata-attributes which are less likely to change. - Blocking and Geo-Targeting.
For that, we used ScrapFly which acts as a proxy and middleware between your scraper and the target website.


