Parsing HTML to locate specific elements on a web page can be a difficult and time-consuming task. But what if we let ChatGPT parse HTML for us?
With ChatGPT HTML parsing, we can find elements in a web page by asking it to generate XPath and CSS selectors for us.
In this article, we will parse HTML with ChatGPT. We'll also learn about web scraping with BeautifulSoup using both XPath and CSS selectors. Let's get into it!
What is ChatGPT HTML Parsing?
To parse HTML with ChatGPT, we'll prompt it for parsing instructions and provide a sample HTML text. It will then identify elements and return the corresponding XPath and CSS selectors.
This method is different compared to Web Scraping using ChatGPT code interpreter. Here, ChatGPT parses HTML only to return selectors, which we will use with BeautifulSoup to complete the web scraping process.
Before we parse HTML with ChatGPT, let's briefly revisit XPath and CSS selectors in web scraping.
XPath Selectors
Elements in an HTML page follow a hierarchical structure, where elements are nested into each other. This structure represents a tree-like structure, which is known as an XML document.
XPath is a tool designed for searching through XML documents. XPath engine uses path expressions to identify and select elements within an XML document. These path expressions consist of a series of steps separated by slashes (/) which point to specific elements in the HTML page.CSS Selectors
CSS Selectors are used to apply styles to elements in a web page. Just like XPath these selectors offer a unique path language for selecting HTML elements to apply style to.This styling creates a combination of types, attributes and states. Based on these combinations, we can target and address HTML elements.
CSS vs XPath?
Both are powerful query languages used in web scraping. To be brief, CSS selectors tend to be more brief and easier while XPath is more powerful and flexible. Many modern web scrapers mix both of these technologies to parse HTML content.
Setup
Before we start let's take a look at what we'll be working with in this article.
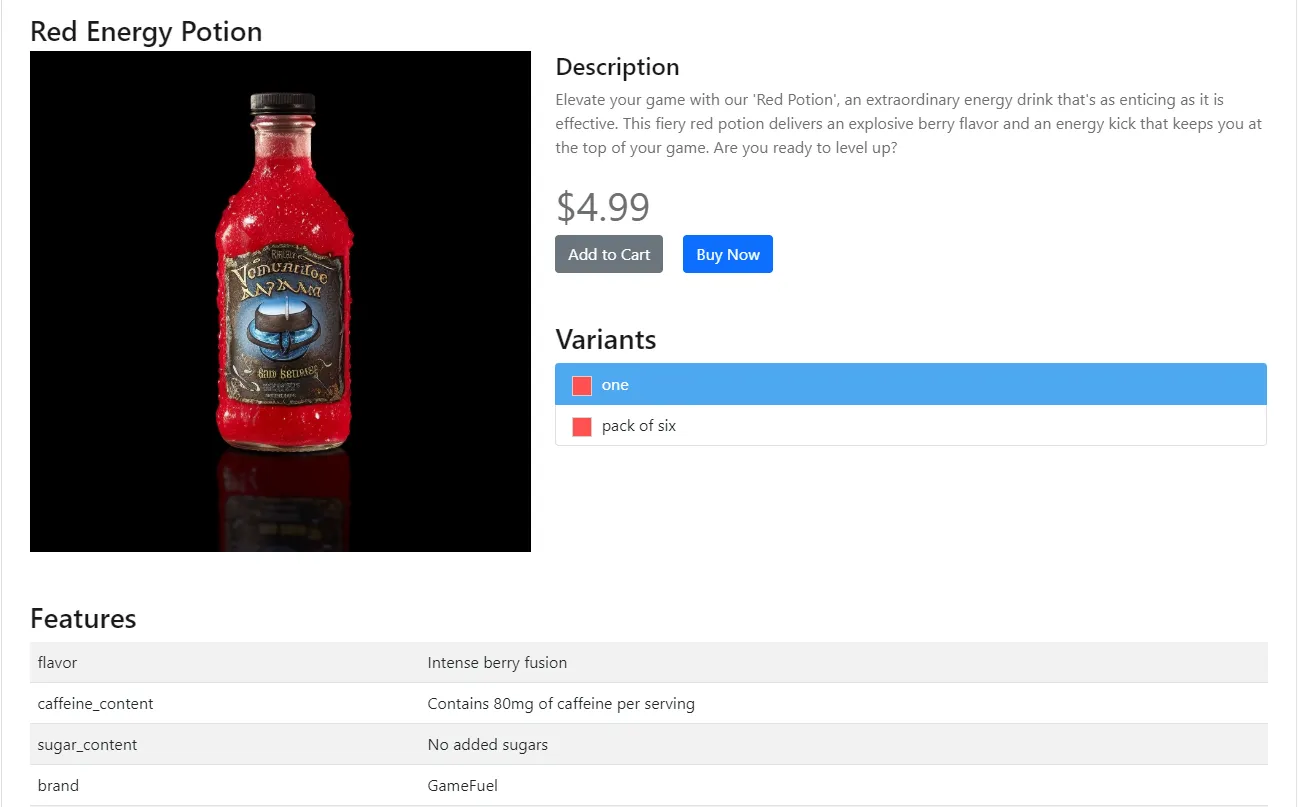
For our scrape example, we'll be using web-scraping.dev/product/4 page:
To evaluate chatgpt results we'll be using parsel and beautifulsoup4 Python packages that can be installed using pip:
$ pip install beautifulsoup4 parsel
🙋We'll be using beautifulsoup4 for CSS selectors and parsel for XPath
Before we parse HTML with ChatGPT, we need to save the example HTML page so we can pass it into the chat prompt.
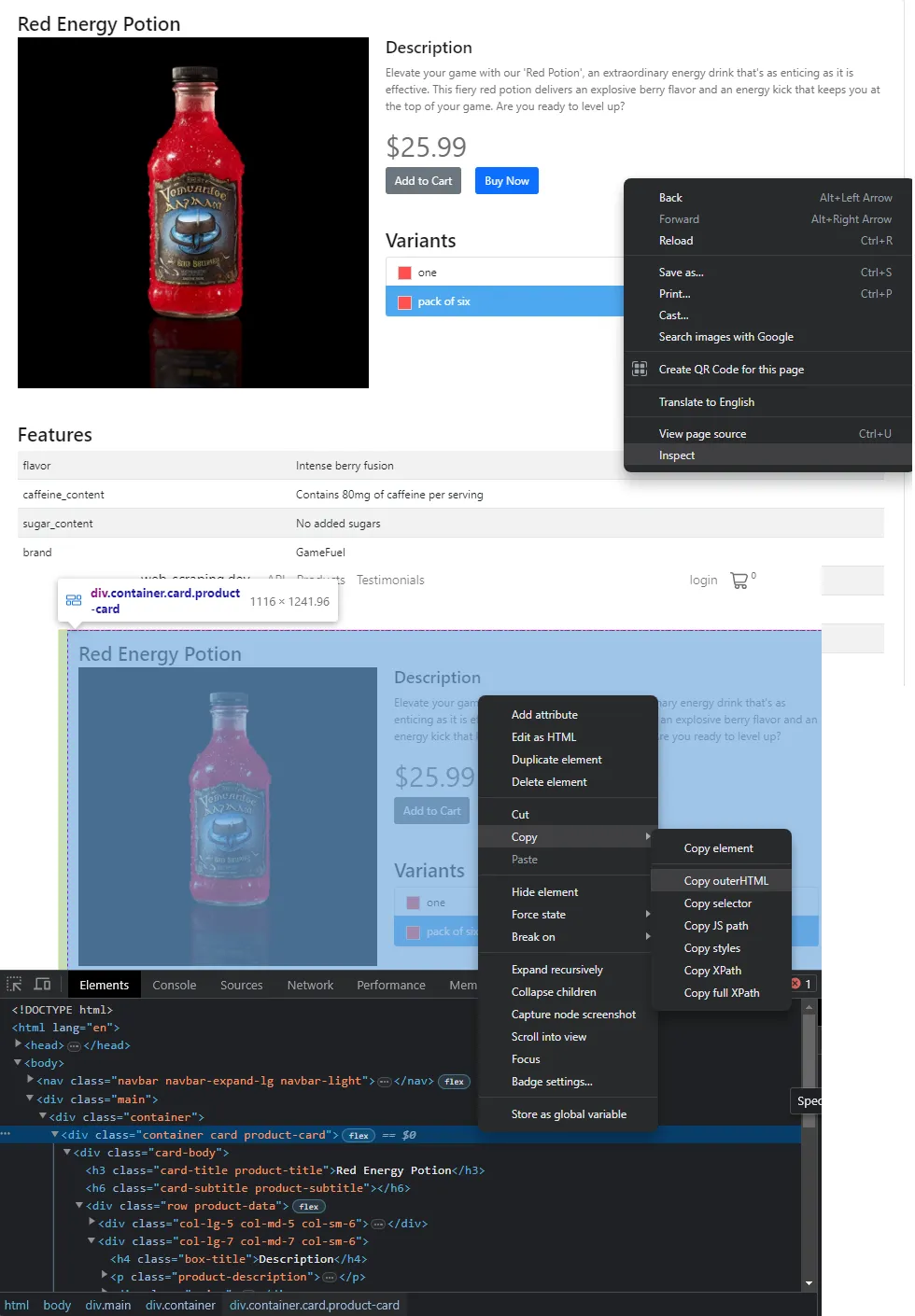
To save the page, simply hit (CTRL + s) and save it as a file or extract the exact snippet using your browser's developer tools (F12 key):
Let's paste the HTML code we copied into the chat prompt and ask for the XPath selectors first using this prompt:

Here are the XPath selectors ChatGPT generated for us using our HTML sample:
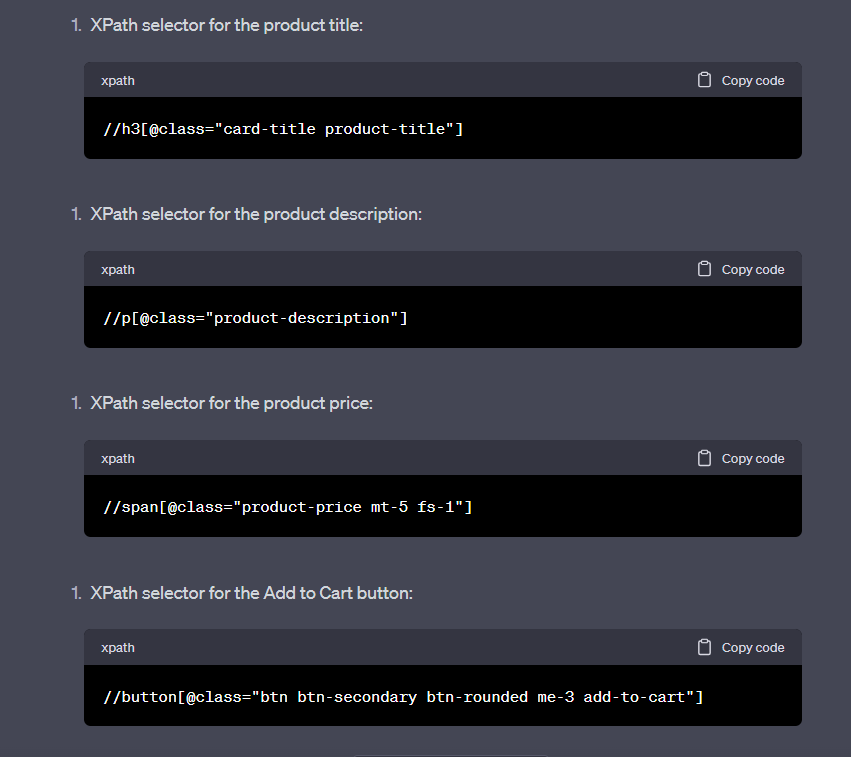
ChatGPT did a great job finding XPath selectors for our HTML sample. It correctly determined what is a product field and correctly identified XPath selectors based on class attribute matching.
However these selectors are still not perfect and we can further prompt it to generate more resistant selectors with prompts like "refine selectors to be more resilient".
Next, why don't we ask ChatGPT for CSS selectors as well:
What about CSS selectors?
ChatGPT's ability to parse HTML feels like magic! It correctly identified relevant data fields in our HTML sample and built both XPath and CSS selectors to target them.
Web Scraping with BeautifulSoup
Now that we parsed the HTML and got XPath and CSS selectors with ChatGPT. Let's put the results to work in our Python scraping code:
from bs4 import BeautifulSoup
import requests
import csv
r = requests.get('https://web-scraping.dev/product/4?variant=one')
soup = BeautifulSoup(r.content, 'html.parser')
First, we import the libraries we will use. Then, we send a request to the target website and load the HTML content as a beautifulsoup4 soup object.
Now, we can create a CSV file object where we'll be storing our scraped data:
filecsv = open('EneryDrink.csv', 'w', encoding='utf8')
csv_columns = ['title', 'description', 'price', 'flavor', 'caffeine_content']
writer = csv.DictWriter(filecsv, fieldnames=csv_columns)
writer.writeheader()
Here, we create an empty CSV file called EneryDrink.csv and create a writer object. The .writeheader() will add the column names to our empty CSV dataset.
Now let's use the XPath and CSS selectors we've got from chatgpt with BeautifulSoup to scrape the product data.
BeautifulSoup with CSS selector
ChatGPT got the CSS selectors for all elements it could find in the HTML we provided. We are only interested in a few elements though, let's scrape them using these ChatGPT CSS selectors:
title = soup.select_one('h3.card-title.product-title').text
description = soup.select_one('p.product-description').text
price = soup.select_one('span.product-price').text
Here, we search for the title, description and price elements using their CSS selectors and use the .text to get the actual text of each web element.
The nested structure of the features table was too complex for ChatGPT to parse. We only got the selectors of the features table itself.
If you take a look at the HTML, you w'll see that the feature values lie in the feature table. It consists of multiple elements and each element has a feature-label and feature-value:
<tbody>
<tr class="feature">
<td width="390" class="feature-label">flavor</td>
<td class="feature-value">Intense berry fusion</td>
</tr>
<tr class="feature">
<td width="390" class="feature-label">caffeine_content</td>
<td class="feature-value">Contains 80mg of caffeine per serving</td>
</tr>
<tr class="feature">..</tr>
<tr class="feature">..</tr>
<tr class="feature">..</tr>
<tr class="feature">..</tr>
<tr class="feature">..</tr>
Use the select method to get all features as an array and filter them by index. Lastly, extend the CSS selector ChatGPT got to capture the feature values. To do that, add td.feature-value to the CSS selector.
flavor = soup.select('table.table.table-striped.table-product tbody tr.feature td.feature-value')[0].text
caffeine_content = soup.select('table.table.table-striped.table-product tbody tr.feature td.feature-value')[1].text
Finally, save the data into the file rows and print out the results:
data = {
'title': title,
'description':description,
'price':price,
'flavor':flavor,
'caffeine_content':caffeine_content
}
writer.writerow(data)
Output Data
Elevate your game with our 'Red Potion', an extraordinary energy drink that's as enticing as it is effective. This fiery red potion delivers an explosive berry flavor and an energy kick that keeps you at the top of your game. Are you ready to level up?
$4.99
Intense berry fusion
Contains 80mg of caffeine per serving
To summarize, here's the final CSS selector code we used to scrape the data:
from bs4 import BeautifulSoup
import requests
import csv
r = requests.get('https://web-scraping.dev/product/4?variant=one')
soup = BeautifulSoup(r.content, 'html.parser')
filecsv = open('EneryDrink.csv', 'w', encoding='utf8')
csv_columns = ['title', 'description', 'price', 'flavor', 'caffeine_content']
writer = csv.DictWriter(filecsv, fieldnames=csv_columns)
writer.writeheader()
title = soup.select_one('h3.card-title.product-title').text
description = soup.select_one('p.product-description').text
price = soup.select_one('span.product-price').text
flavor = soup.select('table.table.table-striped.table-product tbody tr.feature td.feature-value')[0].text
caffeine_content = soup.select('table.table.table-striped.table-product tbody tr.feature td.feature-value')[1].text
writer.writerow({'title': title, 'description':description, 'price':price, 'flavor':flavor, 'caffeine_content':caffeine_content})
Parsel with XPath selectors
We have scraped the page using ChatGPT CSS selectors. Next, let's do the same using the XPath selector.
Since BeautifulSoup doesn't support XPath we'll be using parsel in this section. It implements an XPath selector engine in a similar way that Beautifulsoup implements CSS:
from parsel import Selector
r = requests.get('https://web-scraping.dev/product/4?variant=one')
selector = Selector(text=r.text)
Next, replace the CSS selector code with ChatGPT XPath selectors:
title = selector.xpath('//h3[@class="card-title product-title"]/text()').get()
description = selector.xpath('//p[@class="product-description"]/text()').get()
price = selector.xpath('//span[@class="product-price mt-5 fs-1"]/text()').get()
flavor = selector.xpath('//table[@class="table table-striped table-product"]/tbody/tr[@class="feature"]/td[@class="feature-value"]/text()').getall()[0]
caffeine_content = selector.xpath('//table[@class="table table-striped table-product"]/tbody/tr[@class="feature"]/td[@class="feature-value"]/text()').getall()[1]
We didn't do anything new except searching for elements in the selector object, which represents the XML document. We also added text() to all selecotrs to get the actual text. And just like we did with flavor and caffeine_content before, we added the /td[@class="feature-value"] to get the feature values.
Here is what the full XPath selector code and the sample results it'll produce:
import requests
import csv
from parsel import Selector
r = requests.get('https://web-scraping.dev/product/4?variant=one')
selector = Selector(text=r.text)
filecsv = open('EneryDrink.csv', 'w', encoding='utf8')
csv_columns = ['title', 'description', 'price', 'flavor', 'caffeine_content']
writer = csv.DictWriter(filecsv, fieldnames=csv_columns)
writer.writeheader()
title = selector.xpath('//h3[@class=\"card-title product-title\"]/text()').get()
description = selector.xpath('//p[@class=\"product-description\"]/text()').get()
price = selector.xpath('//span[@class=\"product-price mt-5 fs-1\"]/text()').get()
flavor = selector.xpath('//table[@class=\"table table-striped table-product\"]/tbody/tr[@class=\"feature\"]/td[@class=\"feature-value\"]/text()').getall()[0]
caffeine_content = selector.xpath('//table[@class=\"table table-striped table-product\"]/tbody/tr[@class=\"feature\"]/td[@class=\"feature-value\"]/text()').getall()[1]
writer.writerow({'title': title, 'description':description, 'price':price, 'flavor':flavor, 'caffeine_content':caffeine_content})
print(f"{title}\n{description}\n{price}\n{flavor}\n{caffeine_content}")
Output Data
Elevate your game with our 'Red Potion', an extraordinary energy drink that's as enticing as it is effective. This fiery red potion delivers an explosive berry flavor and an energy kick that keeps you at the top of your game. Are you ready to level up?
$4.99
Intense berry fusion
Contains 80mg of caffeine per serving
Debugging ChatGPT HTML Parsing
While ChatGPT can appear to be quite good at parsing HTML, the final results should be taken with a grain of salt. Here are some follow-up prompts you can use to refine chatgpt's HTML parsing output:
Some selectors can be invalid. You can ask to correct them:
The selector of the title element isn't correct.
Some selectors are generic or have multiple elements. You can request an element name explicitly or request all elements:
Provide the title element selector.
Provide all elements' selectors under the features table.
Some HTML pages use shadow DOM which can be difficult to parse with XPath selector. You can request to change the selector type:
Change the title element selector to CSS selector.
Pages with a lot of information can be too complex for GPT to parse. Try splitting up parsing tasks into smaller chunks:
- Parse product data
- Parse product reviews
FAQ
To wrap up this ChatGPT HTML Parsing guide, let's look at some related frequently asked questions:
Can ChatGPT scrape websites?
Yes, ChatGPT's new code interpreter feature can run code in chat, but you need to pass the HTML through the file upload feature. We have covered Web Scraping using ChatGPT Code Interpreter in a previous tutorial.
How does ChatGPT HTML parsing work?
By passing the HTML of a web page into the chat prompt. ChatGPT parses HTML to locate elements based on selectors like XPath and CSS selectors.
What is the difference between XPath and CSS selectors?
The difference between XPath and CSS selectors is that XPath is more effective at finding elements with no duplicates. Unlike CSS selector which relies on the UI properties, XPath relies on the HTML structure to find elements. Which lets XPath return the same values regardless of the UI changes.
The main downside of XPath is that it's a bit slower than the CSS selector.
Can ChatGPT parse dynamic web pages?
No, currently ChatGPT parses HTML by passing a static HTML file to the chat prompt. Which can be very difficult to do with dynamic web pages as HTML keeps changing. Although, you can use headless browsers for dynamic web scraping.
HTML Parsing with ChatGPT Summary
In this guide, we went through the ChatGPT HTML parsing process, which is locating elements in a web page using selectors like XPath and CSS selectors. We have also explained how to apply XPath and CSS selectors with BeautifulSoup.
While ChatGPT can't perform the whole web scraping process on its own just yet, it can assist with the most time consuming part of the web scraping process - HTML parsing.