Web Scraping Static Paging
Static paging is a classic data pagination technique where every page constains a slice of the dataset. In other words, the data is split into chunks and each URL accesses a specific chunk.

This paging is great for web scraping as it allows to retrieve all pages concurrently. In other words, we can get pages 1,2,3,4,5 at the same time if we know their URLs.
It's called static paging as each slice of the results is a static page/URL. Here are some common URL patterns used in static paging:
- example.com/data?page=1
- example.com/data/page/1
- example.com/data?offset=10
- example.com/data?offset=10&limit=10
- example.com/data?start=10&end=20
While the underlying backend can be different when it comes to scraping we can approach all of these static paging types the same way. Let's take a look at some real examples.
Real Life Example
For this example let's take a look at product paging on web-scraping.dev/products
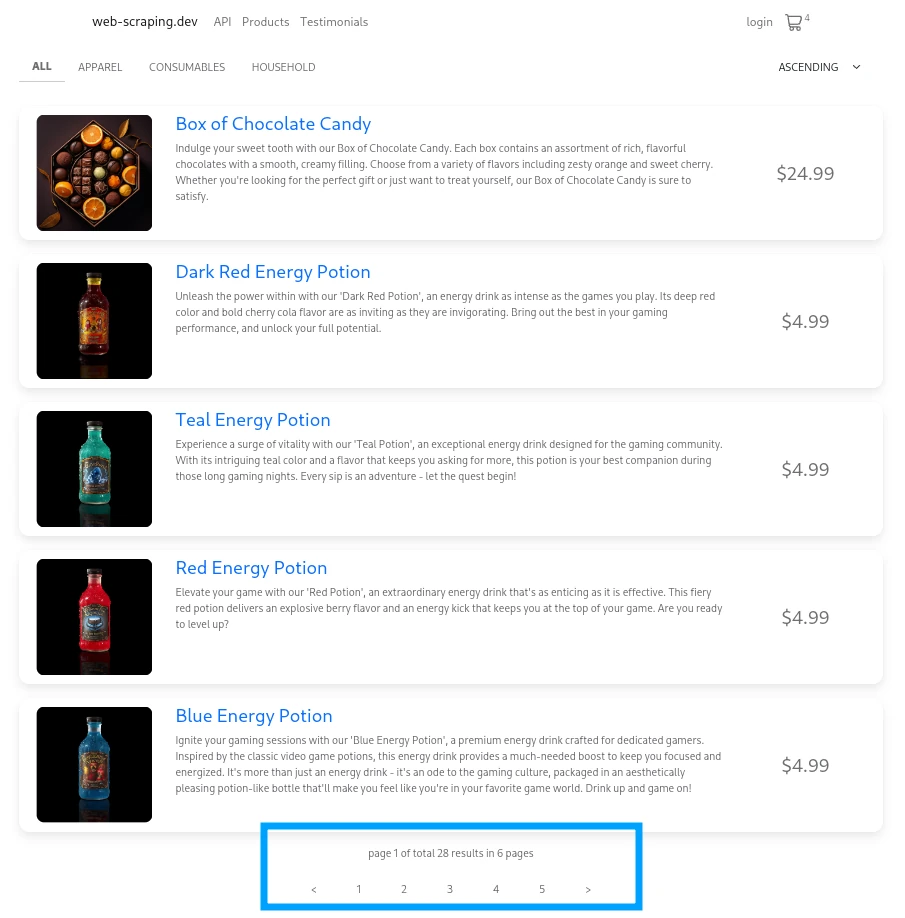
We can identify that it's a static pagination by the navigation at the bottom of the page. We can see links to other pages as well as some metadata about the total paging dataset.
This navigation information provides all of the information we need to scrape the paged dataset:
- The
page=url parameter is responsible for page number. e.g.web-scraping.dev/products?page=2 - There are 5-6 pages in total
- There are 26 results
So to scrape this we can employ a simple scraping algorithm:
- Retrieve the first page
- Find the results on the first page
- Find the total result count or other page urls
- Scrape other pages in a loop
Here's simple code that implements this pagination scraping logic:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
# 1. Get first pagination page
html_result = client.scrape(ScrapeConfig(url="https://web-scraping.dev/products"))
# 2. extract other page urls
other_page_urls = html_result.selector.css(".paging>a::attr(href)").getall()
product_urls = html_result.selector.css(".product h3 a::attr(href)").getall()
print(f"found {len(other_page_urls)} other pages")
# 3. scrape other pagination pages
for url in other_page_urls:
result = client.scrape(ScrapeConfig(url))
product_urls.extend(result.selector.css(".product h3 a::attr(href)").getall())
print(product_urls)
[
"https://web-scraping.dev/product/1",
"https://web-scraping.dev/product/2",
"https://web-scraping.dev/product/3",
"https://web-scraping.dev/product/4",
"https://web-scraping.dev/product/5",
...,
]
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
// 1. Get HTML page for the csrf token
const firstPageResult = await client.scrape(
new ScrapeConfig({ url: 'https://web-scraping.dev/products' }),
);
// 2. extract other page urls and product urls
let selector = cheerio.load(firstPageResult.result.content);
let otherPages = selector(".paging>a").map((i, el) => el.attribs['href']).get();
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
console.log(`found ${otherPages.length} pages`);
// 3. scrape other pagination pages
for (let url of otherPages) {
let result = await client.scrape(
new ScrapeConfig({ url }),
);
// parse other pages just the first one
}
# 1. Get first pagination page
import httpx # or requests
first_page_response = httpx.get(url="https://web-scraping.dev/products")
# 2. extract other page urls
# using parsel
from parsel import Selector
selector = Selector(text=first_page_response.text)
product_urls = selector.css(".product h3 a::attr(href)").getall()
other_page_urls = set(selector.css(".paging>a::attr(href)").getall())
# or using beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(first_page_response.text)
other_page_urls = set([a.attrs["href"] for a in soup.select(".paging>a") if a.attrs.get("href")])
product_urls = [a.attrs["href"] for a in soup.select(".product h3 a")]
print(f"found page urls: {other_page_urls}")
# 3. scrape other pagination pages
for url in other_page_urls:
response = httpx.get(url)
... # parse other pages just like the first one
import axios from 'axios'; // axios as http client
import cheerio from 'cheerio'; // cheerio as HTML parser
// 1. Get the first pagination page
const firstPageResponse = await axios.get("https://web-scraping.dev/products");
// 2. extract other page urls and product urls
let selector = cheerio.load(firstPageResponse.data);
let otherPages = selector(".paging>a").map((i, el) => el.attribs['href']).get();
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
console.log(`found ${otherPages.length} pages`);
// 3. scrape other pagination pages
for (let url of otherPages) {
let response = await axios.get(url);
// parse other pages just the first one
}
We can further improve this code by scraping all pages concurrently as we know the total amount of pages and how URL structure for each page:
import asyncio
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
async def scrape():
result_firstpage = client.scrape(ScrapeConfig("https://web-scraping.dev/products"))
other_page_urls = result_firstpage.selector.css(".paging>a::attr(href)").getall()
product_urls = result_firstpage.selector.css(".product h3 a::attr(href)").getall()
other_pages = [ScrapeConfig(url) for url in other_page_urls]
async for result in client.concurrent_scrape(other_pages):
product_urls.extend(result.selector.css(".product h3 a::attr(href)").getall())
print(product_urls)
asyncio.run(scrape())
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
const firstPageResult = await client.scrape(
new ScrapeConfig({ url: 'https://web-scraping.dev/products' }),
);
let selector = cheerio.load(firstPageResult.result.content);
let otherPages = selector(".paging>a").map((i, el) => el.attribs['href']).get();
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
console.log(`found ${otherPages.length} pages`);
let configs = otherPages.map(url => new ScrapeConfig({url}))
for await (const apiResult of client.concurrentScrape(configs)) {
selector = cheerio.load(apiResult.result.content);
productUrls.push(...selector(".product h3 a").map((i, el) => el.attribs['href']).get());
}
console.log(productUrls);
import asyncio
import httpx
from parsel import Selector
async def scrape():
async with httpx.AsyncClient() as client:
first_page_response = await client.get("https://web-scraping.dev/products")
selector = Selector(text=first_page_response.text)
product_urls = selector.css(".product h3 a::attr(href)").getall()
other_page_urls = set(selector.css(".paging>a::attr(href)").getall())
# to scrape urls concurrently we can use
# asyncio.as_completed or asyncio.gather
for response in asyncio.as_completed([client.get(url) for url in other_page_urls]):
response = await response
selector = Selector(text=first_page_response.text)
product_urls.extend(selector.css(".product h3 a::attr(href)").getall())
print(product_urls)
asyncio.run(scrape())
import axios from 'axios';
import cheerio from 'cheerio';
const firstPageResponse = await axios.get("https://web-scraping.dev/products");
let selector = cheerio.load(firstPageResponse.data);
let otherPages = selector(".paging>a").map((i, el) => el.attribs['href']).get();
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
console.log(`found ${otherPages.length} pages`);
// to scrape concurrently we can use Promise.all()
const allResponses = await Promise.all(otherPages.map(url => axios.get(url)));
for (let resp of allResponses) {
selector = cheerio.load(resp.data);
productUrls.push(...selector(".product h3 a").map((i, el) => el.attribs['href']).get());
}
console.log(productUrls);
Scraping Around Pagination Limits
In this example, we can see that there are only 5 pages displayed but there are 28 results in total. Five results per page times five == 25. We are missing 3 results!
Many websites intentionally limit pagination to either sell the remaining pages or prevent data collection. However, there are ways to address this in web scraping.
To scrape limited pagination we can first try to force URL parameter to see
whether the limit is in the front-end or back-end of the website. In this case
we'd change url parameter to page=6 and see whether we are given
a new set of results.
If the paging limit is on the back-end the only thing we can do is split our paging into multiple sets using filters. For example, on web-scraping.dev we can see we can order the paging in ascending or descending order:
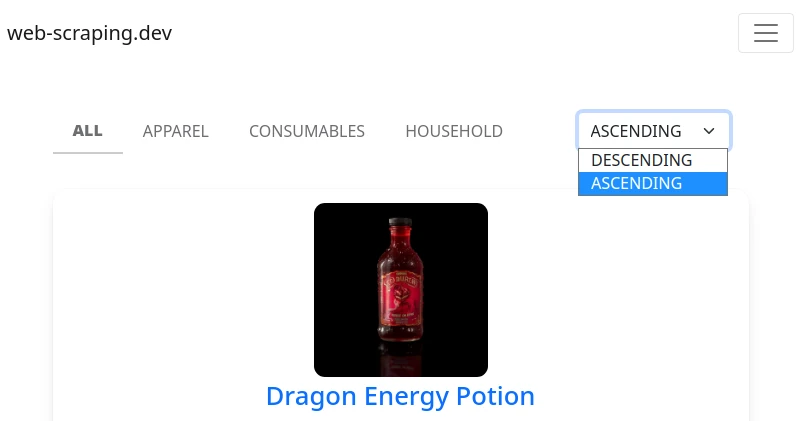
So, in our web-scraping.dev example we can reverse sorting to get those last 3 results. Here's how we can approach this:
- Scrape the first paging page
- Find total mount of results
- Scrape maximum amount of pages in "ASCENDING" order
- Scrape the remaining amount of pages in "DESCENDING" order
Here's how that would look in our scraper:
import asyncio
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
async def scrape():
result_firstpage = client.scrape(ScrapeConfig("https://web-scraping.dev/products"))
product_urls = result_firstpage.selector.css(".product h3 a::attr(href)").getall()
# To start we need to get total amount of pages:
total_pages = int(result_firstpage.selector.css(".paging-meta::text").get().split(" pages")[0].split(" ")[-1])
paging_limit = 5 # this paging limits to max 5 pages
# now can take maximum amount of pages from ascending order:
page_urls = []
_ascending_limit = paging_limit if total_pages > paging_limit else total_pages
for page in range(2, _ascending_limit + 1):
page_urls.append(f"https://web-scraping.dev/products?order=asc&page={page}")
# and take remaining pages from desceding order:
_descending_limit = total_pages - paging_limit
for page in range(1, _descending_limit + 1):
page_urls.append(f"https://web-scraping.dev/products?order=desc&page={page}")
print("scraping urls:")
print("\n".join(page_urls))
# https://web-scraping.dev/products?order=asc&page=2
# https://web-scraping.dev/products?order=asc&page=3
# https://web-scraping.dev/products?order=asc&page=4
# https://web-scraping.dev/products?order=asc&page=5
# https://web-scraping.dev/products?order=desc&page=1
other_pages = [ScrapeConfig(url) for url in page_urls]
async for result in client.concurrent_scrape(other_pages):
product_urls.extend(result.selector.css(".product h3 a::attr(href)").getall())
print(product_urls)
asyncio.run(scrape())
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
// 1. Get HTML page for the csrf token
const firstPageResult = await client.scrape(
new ScrapeConfig({ url: 'https://web-scraping.dev/products' }),
);
// 2. extract other page urls and product urls
let selector = cheerio.load(firstPageResult.result.content);
let otherPages = selector(".paging>a").map((i, el) => el.attribs['href']).get();
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
console.log(`found ${otherPages.length} pages`);
// 3. scrape other pagination pages
for (let url of otherPages) {
let result = await client.scrape(
new ScrapeConfig({ url }),
);
// parse other pages just the first one
}
import asyncio
import httpx
from parsel import Selector
async def scrape():
async with httpx.AsyncClient() as client:
first_page_response = await client.get("https://web-scraping.dev/products")
selector = Selector(text=first_page_response.text)
product_urls = selector.css(".product h3 a::attr(href)").getall()
# To start we need to get the total amount of pages:
total_pages = int(selector.css(".paging-meta::text").get().split(" pages")[0].split(" ")[-1])
paging_limit = 5 # this paging limits to max 5 pages
# now take maximum amount of pages from ascending order:
page_urls = []
_ascending_limit = paging_limit if total_pages > paging_limit else total_pages
for page in range(2, _ascending_limit + 1):
page_urls.append(f"https://web-scraping.dev/products?order=asc&page={page}")
# and take remaining pages from desceding order:
_descending_limit = total_pages - paging_limit
for page in range(1, _descending_limit + 1):
page_urls.append(f"https://web-scraping.dev/products?order=desc&page={page}")
print("scraping urls:")
print("\n".join(page_urls))
# https://web-scraping.dev/products?order=asc&page=2
# https://web-scraping.dev/products?order=asc&page=3
# https://web-scraping.dev/products?order=asc&page=4
# https://web-scraping.dev/products?order=asc&page=5
# https://web-scraping.dev/products?order=desc&page=1
for response in asyncio.as_completed([client.get(url) for url in page_urls]):
response = await response
selector = Selector(text=first_page_response.text)
product_urls.extend(selector.css(".product h3 a::attr(href)").getall())
print(product_urls)
asyncio.run(scrape())
import axios from 'axios';
import cheerio from 'cheerio';
const firstPageResponse = await axios.get("https://web-scraping.dev/products");
let selector = cheerio.load(firstPageResponse.data);
let productUrls = selector(".product h3 a").map((i, el) => el.attribs['href']).get();
// To start we need to get the total amount of pages
let totalPages = parseInt(selector('.paging-meta').text().split(" pages")[0].split(" ").reverse()[0])
const pagingLimit = 5;
// now take maximum amount of pages from ascending order:
let pageUrls = [];
let ascendingLimit = pagingLimit < totalPages ? pagingLimit : totalPages;
for (let page = 2; page <= ascendingLimit; page++) {
pageUrls.push(`https://web-scraping.dev/products?order=asc&page=${page}`);
}
// and then take remaining pages from descending order:
let descendingLimit = totalPages - pagingLimit;
for (let page = 1; page <= descendingLimit; page++) {
pageUrls.push(`https://web-scraping.dev/products?order=desc&page=${page}`);
}
console.log("scraping urls", pageUrls);
// scrape all concurrently as usual:
const allResponses = await Promise.all(pageUrls.map(url => axios.get(url)));
for (let resp of allResponses) {
selector = cheerio.load(resp.data);
productUrls.push(...selector(".product h3 a").map((i, el) => el.attribs['href']).get());
}
console.log(productUrls);
Above, is a popular algorithm for scraping pagination from two ends of the pagination. This approach doubles the amount of results we can access. Though, if a search offers more sorting options or different filters the same idea can be applied there to get around most pagination limits!