CSRF Header in Web Scraping
CSRF tokens are used to prevent hijacking of backend API calls. They work by setting a secret token on one page and expecting it on another. Here's a quick illustration:

So, the 2nd page cannot be accessed unless the client had access to the first one to get the token.
In web scraping, this is mostly encountered when scraping the website's backend API which locks the data endpoints with a CSFR token requirement to prevent direct API calls.
Usually, the CSRF token is stored in:
inputHTML element like<input name="csrf" value="123">- Javascript variable in
<script>element like<script>var csrf="123";</script>
Then the CSRF token is passed to the 2nd page through HTTP headers like:
X-CSRFX-CSRF-TokenX-XSRF-Token
Finally, CSRF tokens can be single-use, multi-use or even time limited.
Real Life Example
Let's take a look at an example CSRF use case scenario featured web-scraping.dev platform for web scraper testing.
The product pages like /product/1 are using CSRF token in the API call to load more reviews.
To observe that, click the "Load More" button and take a look at the Network Tab of
our browser devtools (e.g. F12 key in Chrome), we can see that a request for more reviews is sent.
This request contains a x-csrf-token header:
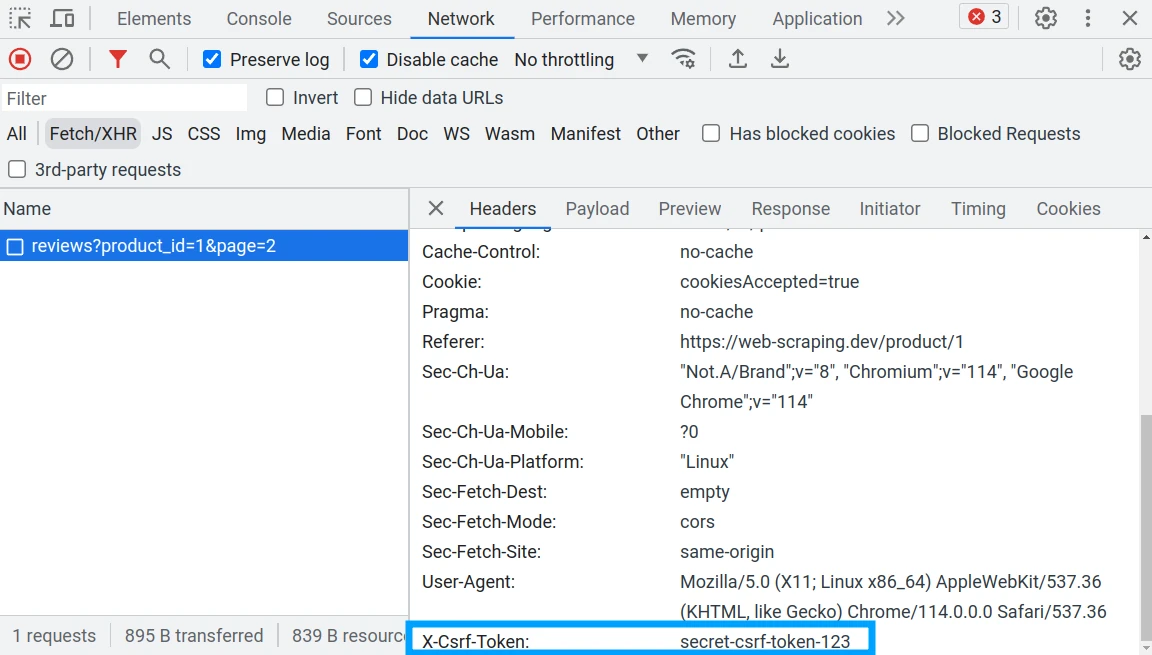
If we were to replicate this request without including this header
we'd get a code 4xx response:
from scrapfly import ScrapflyClient, ScrapeConfig, UpstreamHttpClientError
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
try:
result = client.scrape(
ScrapeConfig(
url="https://web-scraping.dev/api/reviews?product_id=1&page=2",
)
)
except UpstreamHttpClientError as e:
print(f"rejected, got response code: {e.http_status_code}")
# 422
print(e.api_response.content)
# {"detail":[{"loc":["header","x-csrf-token"],"msg":"field required","type":"value_error.missing"}]}
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
try {
const apiResponse = await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/api/reviews?product_id=1&page=2',
}),
);
console.log(apiResponse);
} catch (error) {
console.error(`reason: ${error}`);
console.error(error.args.api_response.result.content);
/*
reason: Error: The website you target respond with an unexpected status code (>400) - The website you scrape respond with: 422 - Unprocessable Entity
{"detail":[{"loc":["header","x-csrf-token"],"msg":"field required","type":"value_error.missing"}]}
*/
}
import httpx # or requests
response = httpx.get("https://web-scraping.dev/api/reviews?product_id=1&page=2")
if response.status_code != 200:
print(f"rejected, got response code: {response.status_code}")
print(response.json())
# rejected, got response code: 422
# {'detail': [{'loc': ['header', 'x-csrf-token'], 'msg': 'field required', 'type': 'value_error.missing'}]}
import axios from 'axios'; // axios as http client
try {
const response = await axios.get(
"https://web-scraping.dev/api/reviews?product_id=1&page=2"
);
console.log(response.data);
} catch (error) {
console.error(`rejected, got response code: ${error.response.status}`);
console.error(`reason: ${JSON.stringify(error.response.data)}`);
}
/*
rejected, got response code: 422
reason: {"detail":[{"loc":["header","x-csrf-token"],"msg":"field required","type":"value_error.missing"}]}
*/
Now that we know that CSRF token is required - how do we find it?
We already identified possible locations of the token at the beginning of this article - HTML element, script or Local Storage - though the most likely place is the HTML element.
In this example, if we ctrl+f the token in the page source,
we can find it in the HTML element:
<input type="hidden" name="csrf-token" value="secret-csrf-token-123">
To replicate this behavior in our scraper, we need to:
- Retrieve the HTML page with the hidden token (the product page)
- Parse the HTML and find the token
- Include token in our API requests
We can achieve this in a few lines of code:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
# 1. Get HTML page for the csrf token
html_result = client.scrape(ScrapeConfig(url="https://web-scraping.dev/product/1"))
# 2. extract CSRF token
csrf_token = html_result.selector.css("input[name=csrf-token]::attr(value)").get()
# 3. scrape hidden API
api_result = client.scrape(
ScrapeConfig(
url="https://web-scraping.dev/api/reviews?product_id=1&page=2",
headers={"X-Csrf-Token": csrf_token},
)
)
print(api_result.content)
{
"order": "asc",
"category": None,
"total_results": 10,
"next_url": None,
"results": [
{
"id": "chocolate-candy-box-6",
"text": "Bought the large box, and it's lasted quite a while. Great for when you need a sweet treat.",
"rating": 5,
"date": "2022-12-18",
},
...,
],
"page_number": 2,
"page_size": 5,
"page_total": 2,
}
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
// 1. Get HTML page for the csrf token
const apiResponse = await client.scrape(
new ScrapeConfig({ url: 'https://web-scraping.dev/product/1' }),
);
// 2. extract CSRF token. Here we are using cheerio and CSS selector
const selector = cheerio.load(apiResponse.result.content);
const csrf = selector("input[name=csrf-token]").attr("value")
console.log(`found csrf token: ${csrf}`);
// 3. scrape hidden API
const apiResponse2 = await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/api/reviews?product_id=1&page=2',
headers: { 'X-Csrf-Token': csrf }
}),
);
console.log(apiResponse2.result.content);
/*
{
"order": "asc",
"category": null,
"total_results": 10,
"next_url": null,
"results": [
{
"id": "chocolate-candy-box-6",
"text": "Bought the large box, and it's lasted quite a while. Great for when you need a sweet treat.",
"rating": 5,
"date": "2022-12-18",
},
...
],
"page_number": 2,
"page_size": 5,
"page_total": 2,
}
*/
# 1. Get HTML page for the csrf token
import httpx # or requests
html_response = httpx.get(url="https://web-scraping.dev/product/1")
# 2. extract csrf token
# using parsel
from parsel import Selector
selector = Selector(text=html_response.text)
csrf_token = selector.css("input[name=csrf-token]::attr(value)").get()
# or using beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_response.text)
csrf_token = soup.select("input[name=csrf-token]")[0].attrs["value"]
print(f"using csrf token: {csrf_token}")
# 3. scrape hidden API
api_response = httpx.get(
url="https://web-scraping.dev/api/reviews?product_id=1&page=2",
headers={"X-Csrf-Token": csrf_token},
)
print(api_response.json())
{
"order": "asc",
"category": None,
"total_results": 10,
"next_url": None,
"results": [
{
"id": "chocolate-candy-box-6",
"text": "Bought the large box, and it's lasted quite a while. Great for when you need a sweet treat.",
"rating": 5,
"date": "2022-12-18",
},
...,
],
"page_number": 2,
"page_size": 5,
"page_total": 2,
}
import axios from 'axios'; // axios as http client
import cheerio from 'cheerio'; // cheerio as HTML parser
// 1. Get HTML page for the csrf token
const htmlResponse = await axios.get("https://web-scraping.dev/product/1");
// 2. extract CSRF token. Here we are using cheerio and CSS selector
const selector = cheerio.load(htmlResponse.data);
const csrf = selector("input[name=csrf-token]").attr("value")
console.log(`found csrf token: ${csrf}`);
// 3. scrape hidden API
const apiResponse = await axios.get(
"https://web-scraping.dev/api/reviews?product_id=1&page=2",
{ headers: { "X-Csrf-Token": csrf } }
);
console.log(apiResponse.data)
/*
{
"order": "asc",
"category": null,
"total_results": 10,
"next_url": null,
"results": [
{
"id": "chocolate-candy-box-6",
"text": "Bought the large box, and it's lasted quite a while. Great for when you need a sweet treat.",
"rating": 5,
"date": "2022-12-18",
},
...
],
"page_number": 2,
"page_size": 5,
"page_total": 2,
}
*/
In the example code above, we retrieve the HTML page containing the CSRF token, extract it using an HTML parser and then we can successfully scrape the reviews backend API.
CSRF Alternatives
Many different similar header tokens provide the same function - locking down page access. Though almost all of them follow the same pattern - provide the client the token and expect it later on.
These type of headers are usually prefixed with X- which indicates that it's not a standard
web browser header.