Web Scraping Endless Paging
Endless paging also known as dynamic or interactive paging is a data pagination technique where every page is loaded dynamically on user action like scroll or a button press.

This paging method can be difficult to scrape as it requires reverse engineering knowledge to replicate the actions browser performs in the background to load next page data. Let's take a look at a real-life example to learn more.
Real Life Example
For this example let's take a look at the testominial paging on web-scraping.dev/testimonials
We can see that testimonial results keep appearing as we scroll down in our browser window. We can confirm this further by disabling javascript which will only show the first set of testimonials.
To scrape this we have two options:
- Reverse engineer the way paging works and replicate it in our scraper
- Use browser automation tools like Playwright, Puppeteer or Selenium to emulate paging load actions
Both of these methods are valid and while the 1st one is a bit more difficult it's much more efficient. Let's take a look at it first.
Reverse Engineering Endless Paging
Using browser developer tools (F12 key) Network Tab we can observe XHR-type requests when triggering page load actions such as scrolling:
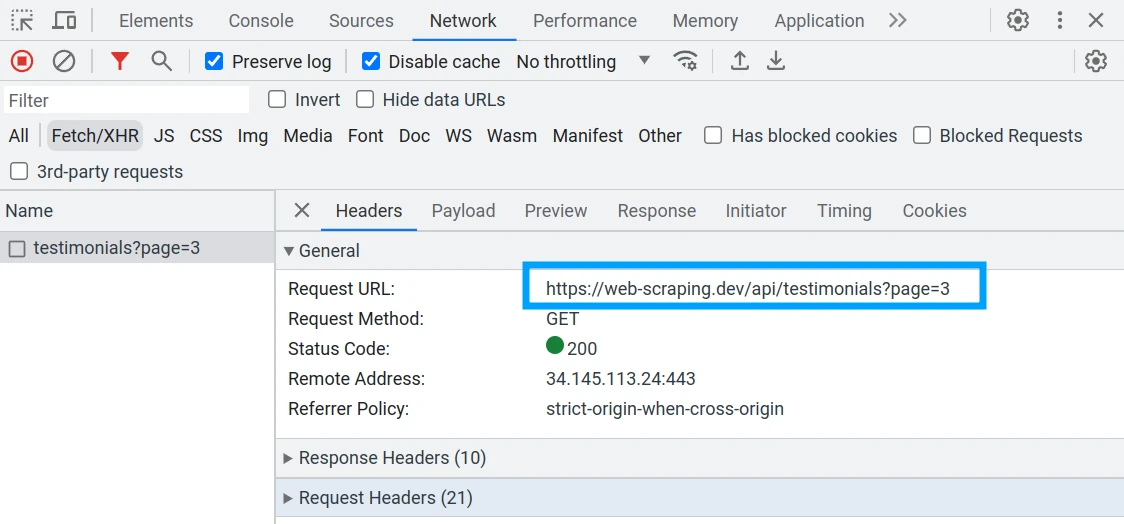
In our web-scraping.dev example we can see an XHR request is being made every time we scroll to the end of the page. This backend XHR request contains data for the next page. Let's see how to replicate this in web scraping:
from scrapfly import ScrapflyClient, ScrapeConfig, UpstreamHttpClientError
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
HEADERS = {"Referer": "https://web-scraping.dev/testimonials"}
page_results = []
page = 1
while True:
try:
result = client.scrape(
ScrapeConfig(
f"https://web-scraping.dev/api/testimonials?page={page}",
headers=HEADERS,
)
)
except UpstreamHttpClientError:
break
page_results.append(result.content)
page += 1
print(f"scraped {len(page_results)} pages")
# scraped 6 pages
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
const HEADERS = { "Referer": "https://web-scraping.dev/testimonials" };
let pageResults = [];
let page = 1;
while (true) {
try {
const result = await client.scrape(
new ScrapeConfig({
url: `https://web-scraping.dev/api/testimonials?page=${page}`,
headers: HEADERS,
}),
);
pageResults.push(result.result.content);
page += 1;
} catch {
break;
}
}
console.log(`Scraped ${pageResults.length} pages`);
// scraped 6 pages
import httpx # or requests
# note: /testominials endpoit requires a referer header:
HEADERS = {"Referer": "https://web-scraping.dev/testimonials"}
page_results = []
page = 1
while True:
response = httpx.get(f"https://web-scraping.dev/api/testimonials?page={page}", headers=HEADERS)
if response.status_code != 200:
break
page_results.append(response.text)
page += 1
print(f"scraped {len(page_results)} pages")
# scraped 6 pages
import axios from 'axios'; // axios as http client
const HEADERS = {"Referer": "https://web-scraping.dev/testimonials"};
let pageResults = [];
let page = 1;
while (true) {
try {
const response = await axios.get(`https://web-scraping.dev/api/testimonials?page=${page}`, { headers: HEADERS });
if (response.status !== 200) {
break;
}
pageResults.push(response.data);
page += 1;
} catch (error) {
break;
}
}
console.log(`Scraped ${pageResults.length} pages`);
// scraped 6 pages
Above, we are replicating the endless scroll pagination by calling the backend API directly in a scraping loop until we receive no more results.
Endless Paging with Headless Browsers
Alternatively, we can run an entire headless browser and tell it to perform the dynamic paging actions to load of the paging data and then retrieve it.
There are a few ways to approach this and for that let's take a look at out web-scraping.dev example again.
The first approach is to load the /testimonials page and scroll to the bottom of the page and then collect all results:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
result = client.scrape(
ScrapeConfig(
"https://web-scraping.dev/testimonials",
render_js=True, # enable javascript rendering through headless browsers
auto_scroll=True, # scroll to the bottom of the page
)
)
testimonials = result.selector.css(".testimonial .text::text").getall()
print(f"scraped {len(testimonials)} testimonials")
# scraped 40 testimonials
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
const result = await client.scrape(
new ScrapeConfig({
url: "https://web-scraping.dev/testimonials",
render_js: true, // enable javascript rendering through headless browsers
auto_scroll: true, // scroll to the bottom of the page
}),
);
let selector = cheerio.load(result.result.content);
let testimonials = selector(".testimonial .text").map((i, el) => selector(el).text()).get();
console.log(`Scraped ${testimonials.length} testimonials`);
// scraped 40 testimonials
# This example is using Playwright but it's also possible to use Selenium with similar approach
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://web-scraping.dev/testimonials/")
# scroll to the bottom:
_prev_height = -1
_max_scrolls = 100
_scroll_count = 0
while _scroll_count < _max_scrolls:
# Execute JavaScript to scroll to the bottom of the page
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Wait for new content to load (change this value as needed)
page.wait_for_timeout(1000)
# Check whether the scroll height changed - means more pages are there
new_height = page.evaluate("document.body.scrollHeight")
if new_height == _prev_height:
break
_prev_height = new_height
_scroll_count += 1
# now we can collect all loaded data:
results = []
for element in page.locator(".testimonial").element_handles():
text = element.query_selector(".text").inner_html()
results.append(text)
print(f"scraped {len(results)} results")
# scraped 40 results
// This example is using puppeteer but it's also possible to use Playwright with almost identical API
const puppeteer = require('puppeteer');
async function scrapeTestimonials() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://web-scraping.dev/testimonials/');
let prevHeight = -1;
let maxScrolls = 100;
let scrollCount = 0;
while (scrollCount < maxScrolls) {
// Scroll to the bottom of the page
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
// Wait for page load
await page.waitForTimeout(1000);
// Calculate new scroll height and compare
let newHeight = await page.evaluate('document.body.scrollHeight');
if (newHeight == prevHeight) {
break;
}
prevHeight = newHeight;
scrollCount += 1;
}
// Collect all loaded data
let elements = await page.$$('.testimonial');
let results = [];
for(let element of elements) {
let text = await element.$eval('.text', node => node.innerHTML);
results.push(text);
}
console.log(`Scraped ${results.length} results`);
// Scraped 40 results
await browser.close();
}
scrapeTestimonials();
Using headless browsers is a much more simple and elegant solution however as we're using a real browser we use significantly more resources
So, whether to reverse-engineer backend API or use a headless browser depends on available resources and the complexity of the targeted system.