Referer Header in Web Scraping
The word Referer is officially mispelled. Natural English spelling is Referrer (note the double r), but it has been adopted to the HTTP standard before it could be fixed.
The Referer header identifies what referred the client to this page. In other words, it indicates the last page the client was on before the current one.

The Referer can be used to lock certain areas of the page to specific browsing patterns. For example, product reviews should only be visible to clients who are coming from the product page.
This pattern is often encountered in web scraping where the
Referer header is being used to prevent pages from being scraped or accidentally
accessed through unsupported means.
Referer can also play a role in web scraper blocking through
browsing pattern tracking. In other words, if your scraper is not sending Referer but
every real user is - then it's easy to detect your scraper.
So, it's important to consider this header and ensure it behaves naturally when
scaling up web scrapers.
Real Life Example
To illustrate this, let's take a look at Referer-locked page example on web-scraping.dev
The backend API used to paginate the /testimonials page
requires a Referer header to be set to the current page URL to respond with data.
We can observe this by taking a look at the Developer Tools (F12 key) and inspecting the Network Tab.
As we scroll the page web-scraping.dev is making requests to backend API to fetch more testimonials.
In each of these requests, the browser is automatically adding Referer header.
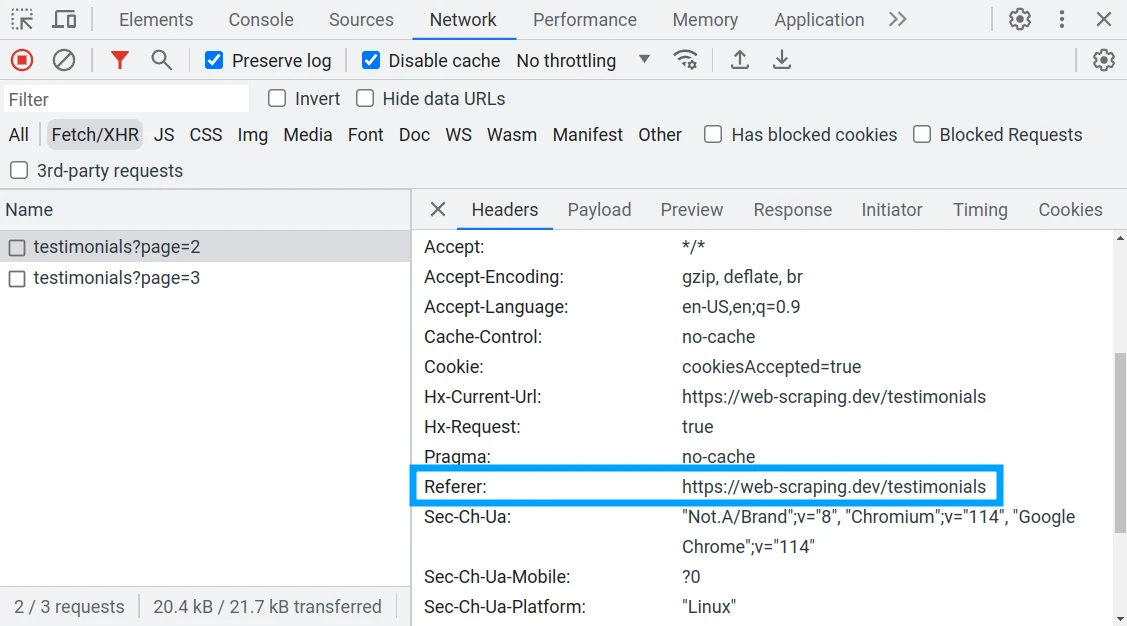
The Referer includes the complete URL of the page we are coming from
with the URL anchor removed (everything that comes after # symbol).
Without the Referer header the web-scraping.dev API will
response with 4xx response code:
from scrapfly import ScrapflyClient, ScrapeConfig, UpstreamHttpClientError
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
try:
result = client.scrape(
ScrapeConfig(
url="https://web-scraping.dev/api/testimonials",
)
)
except UpstreamHttpClientError as e:
print(f"rejected, got response code: {e.http_status_code}")
# 422
print(e.api_response.content)
# {"detail":[{"loc":["header","referer"],"msg":"field required","type":"value_error.missing"}]}
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
try {
const apiResponse = await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/api/testimonials',
}),
);
console.log(apiResponse);
} catch (error) {
console.error(`reason: ${error}`);
console.error(error.args.api_response.result.content);
/*
reason: Error: The website you target respond with an unexpected status code (>400) - The website you scrape respond with: 422 - Unprocessable Entity
{"detail":[{"loc":["header","referer"],"msg":"field required","type":"value_error.missing"}]}
*/
}
import httpx # or requests
response = httpx.get("https://web-scraping.dev/api/testimonials")
if response.status_code != 200:
print(f"rejected, got response code: {response.status_code}")
print(response.json())
# {"detail":[{"loc":["header","referer"],"msg":"field required","type":"value_error.missing"}]}
import axios from 'axios'; // axios as http client
try {
const response = await axios.get("https://web-scraping.dev/api/testimonials");
console.log(response.data);
} catch (error) {
console.error(`rejected, got response code: ${error.response.status}`);
console.error(`reason: ${JSON.stringify(error.response.data)}`);
}
/*
rejected, got response code: 422
reason: {"detail":[{"loc":["header","referer"],"msg":"field required","type":"value_error.missing"}]}
*/
To fix this, let's include Referer in our headers. Usually, the Referer is set to the current or previous URL in the browsing session.
in web-scraping.dev example we have to set it to the testimonials home page:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
api_result = client.scrape(
ScrapeConfig(
url="https://web-scraping.dev/api/testimonials", headers={"Referer": "https://web-scraping.dev/testimonials"}
)
)
print(len(api_result.content))
# 10338
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
const apiResponse = await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/api/testimonials',
headers: {
Referer: 'https://web-scraping.dev/testimonials'
}
}),
);
console.log(apiResponse.result.content.length);
// 10338
import httpx # or requests
response = httpx.get(
"https://web-scraping.dev/api/testimonials",
headers={
"Referer": "https://web-scraping.dev/testimonials",
},
)
print(response.status_code)
# 200
print(len(response.text))
# 10338
import axios from 'axios'; // axios as http client
const response = await axios.get(
"https://web-scraping.dev/api/testimonials",
{ headers: {'Referer': 'https://web-scraping.dev/testimonials'}}
);
console.log(response.data.length);
// 10338