Cookies in Web Scraping
Cookies are small data values stored on the client's system by the server. They are used to track the client's state and capabilities like login authentication.

Each request made by the client is sending the entire cookie set to the server and each response can add or modify the client's cookies.
Cookies play a role in many different web functionalities encountered in web scraping:
- Login authentication
- Session details like the current step in a checkout process
- Preference configuration like site language and currency
- Client tracking
Most importantly, cookies are just request headers and are treated the same way as any other header except cookie values can expire or become invalidated.
Cookies play an important role in a web scraping process. Probably the most commonly encountered cookie use is authentication. Let's take a real life example.
Real Life Example
For this example, let's take a look at web-scraping.dev/login page, how it's using cookies for login authentication and how to scrape it.
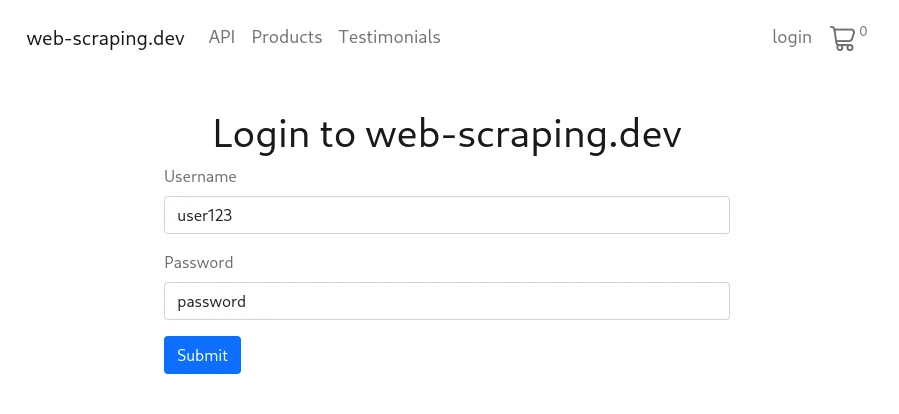
If we press the "Submit" button and perform our login in the browser Developer Tools (F12 key) network tab we can see that the returned response comes with a `Set-Cookie` header:
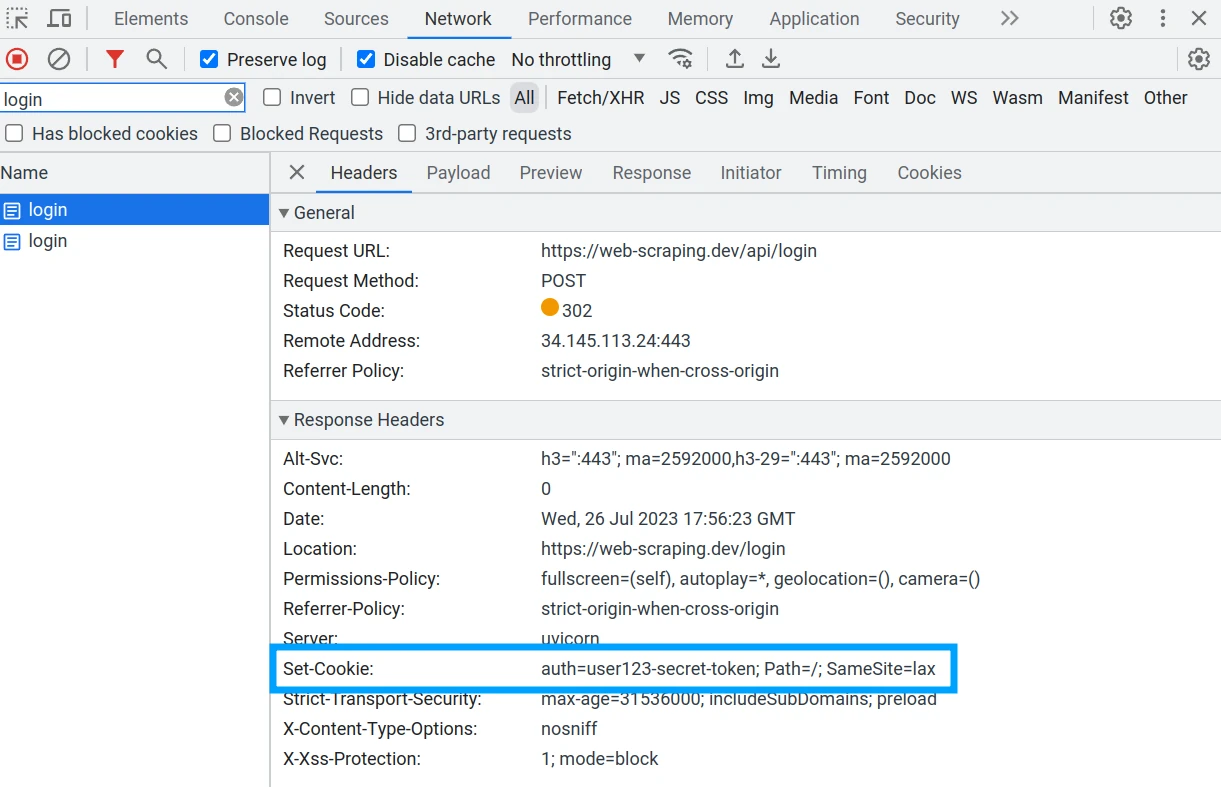
This header contains a secret authentication token that will allow the client to
access areas of the site that require login. Now, every request on web-scraping.dev
will include a Cookie header with this secret value:
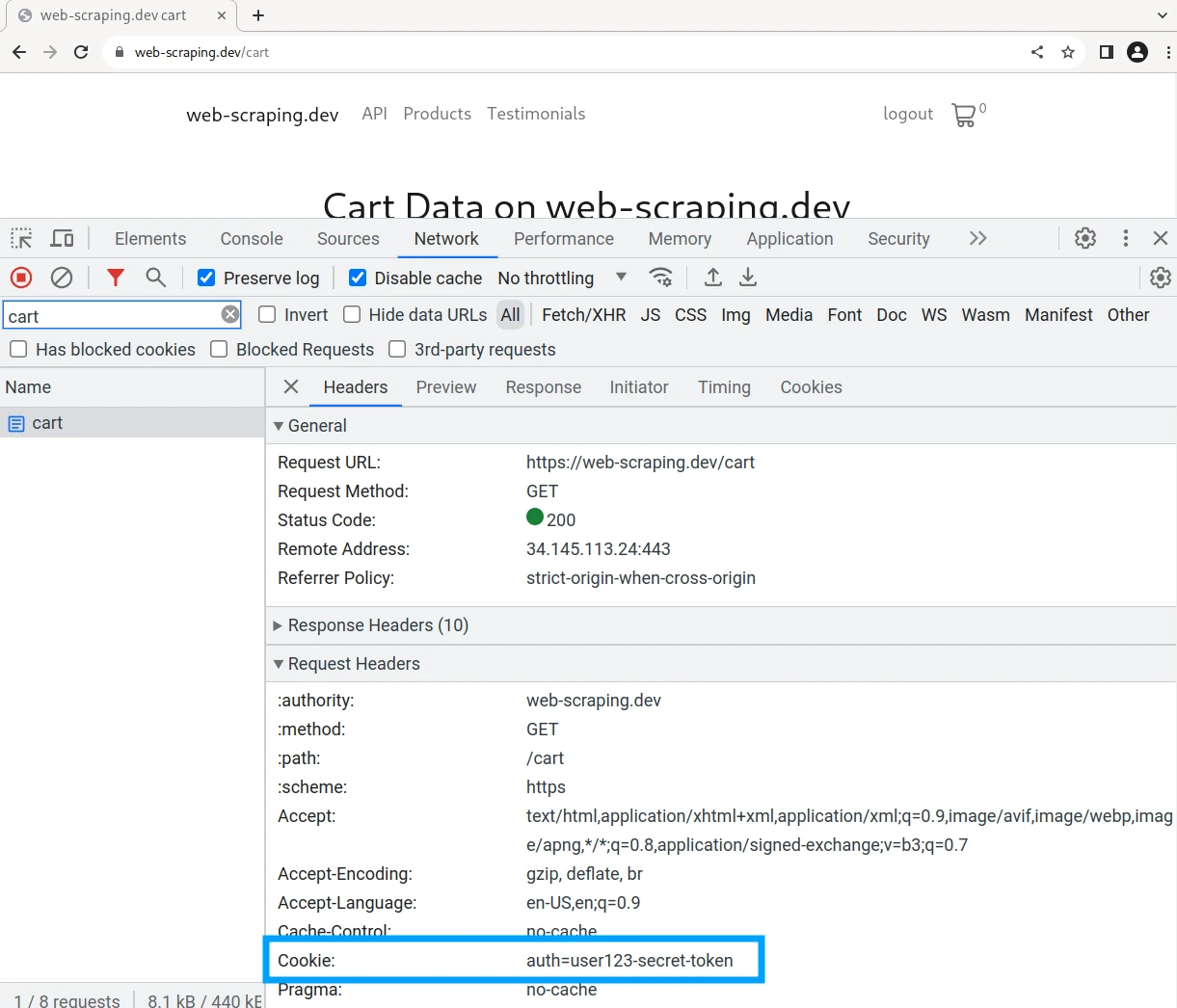
To replicate this behavior in our web scraper we need to:
- Generate the
Set-Cookieresponse header and save the value - Include the
Cookierequest header with this secret value
In this web-scraping.dev example we generate the cookie by submitting a correct login form. Let's take a look at how it all works together:
from scrapfly import ScrapflyClient, ScrapeConfig, UpstreamHttpClientError
import uuid
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
session = str(uuid.uuid4()).replace("-", "")
login = client.scrape(
ScrapeConfig(
url="https://web-scraping.dev/api/login",
session=session,
debug=True,
method="POST",
data={
"username": "user123",
"password": "password",
},
)
)
secret = client.scrape(ScrapeConfig("https://web-scraping.dev/login", session=session))
secret_value = secret.selector.css("#secret-message::text").get()
print(secret_value)
import { ScrapflyClient, ScrapeConfig } from 'scrapfly-sdk';
import { v4 as uuidv4 } from 'uuid';
import cheerio from 'cheerio';
const client = new ScrapflyClient({ key: "YOUR SCRAPFLY KEY" });
// create a session
const session = uuidv4();
// login current sesion:
await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/api/login',
session: session,
method: "POST",
data: {
username: "user123",
password: "password",
}
}),
);
// cookies will automatically be used for request with the same session:
const secretResult = await client.scrape(
new ScrapeConfig({
url: 'https://web-scraping.dev/login',
session: session,
}),
);
let $ = cheerio.load(secretResult.result.content);
let secret = $('#secret-message').text();
console.log(secret);
import httpx # or requests
# 1. Perform login POST request to get authentication cookies:
login_response = httpx.post(
"https://web-scraping.dev/api/login",
data={
"username": "user123",
"password": "password",
},
)
print(dict(login_response.cookies))
{"auth": "user123-secret-token"}
# 2. use cookies in following requests:
secret_response = httpx.get("https://web-scraping.dev/login", cookies=dict(login_response.cookies))
# find secret message only available to logged in users:
from parsel import Selector
secret = Selector(secret_response.text).css("#secret-message::text").get()
print(secret)
# 🤫
# ALTERNATIVE:
# httpx can track cookies automatically when httpx.Client() or httpx.AsyncClient() is used.
with httpx.Client() as client:
login_response = httpx.post(
"https://web-scraping.dev/api/login",
data={
"username": "user123",
"password": "password",
},
)
secret_response = client.get("https://web-scraping.dev/login")
# find secret message only available to logged in users:
from parsel import Selector
secret = Selector(secret_response.text).css("#secret-message::text").get()
print(secret)
import axios from 'axios';
import cheerio from 'cheerio';
// 1. Perform login POST request to get authentication cookies
let data = new URLSearchParams();
data.append('username', 'user123');
data.append('password', 'password');
let loginResponse = await axios.post('https://web-scraping.dev/api/login', data.toString(), {
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
maxRedirects: 0, // Prevent axios from following redirects
validateStatus: false,
});
const cookies = loginResponse.headers['set-cookie'];
console.log(cookies); // 'set-cookie' headers
// 2. Use cookies in following requests
let secretResponse = await axios.get('https://web-scraping.dev/login', {
headers: {
'Cookie': cookies.join(';'), // Send cookies in 'Cookie' header
},
});
// Find secret message only available to logged in users
let $ = cheerio.load(secretResponse.data);
let secret = $('#secret-message').text();
console.log(secret);
// 🤫
Above we're treating cookies as normal header values. The initial login request receives set-cookie header with our user's password and then we can use it to scrape all endpoints that require authentication.