Screenshot
Scrapfly's screenshot feature allows to capture a screenshot of the scraped web page. These screenshots can be full page or focused on specific HTML elements via CSS selectors.
Screenshots feature requires Javascript Rendering enabled
Captured screenshots are stored on Scrapfly's servers and the URLs are available in the API response under
result.screenshots key as well as monitoring logs Screenshot tab:
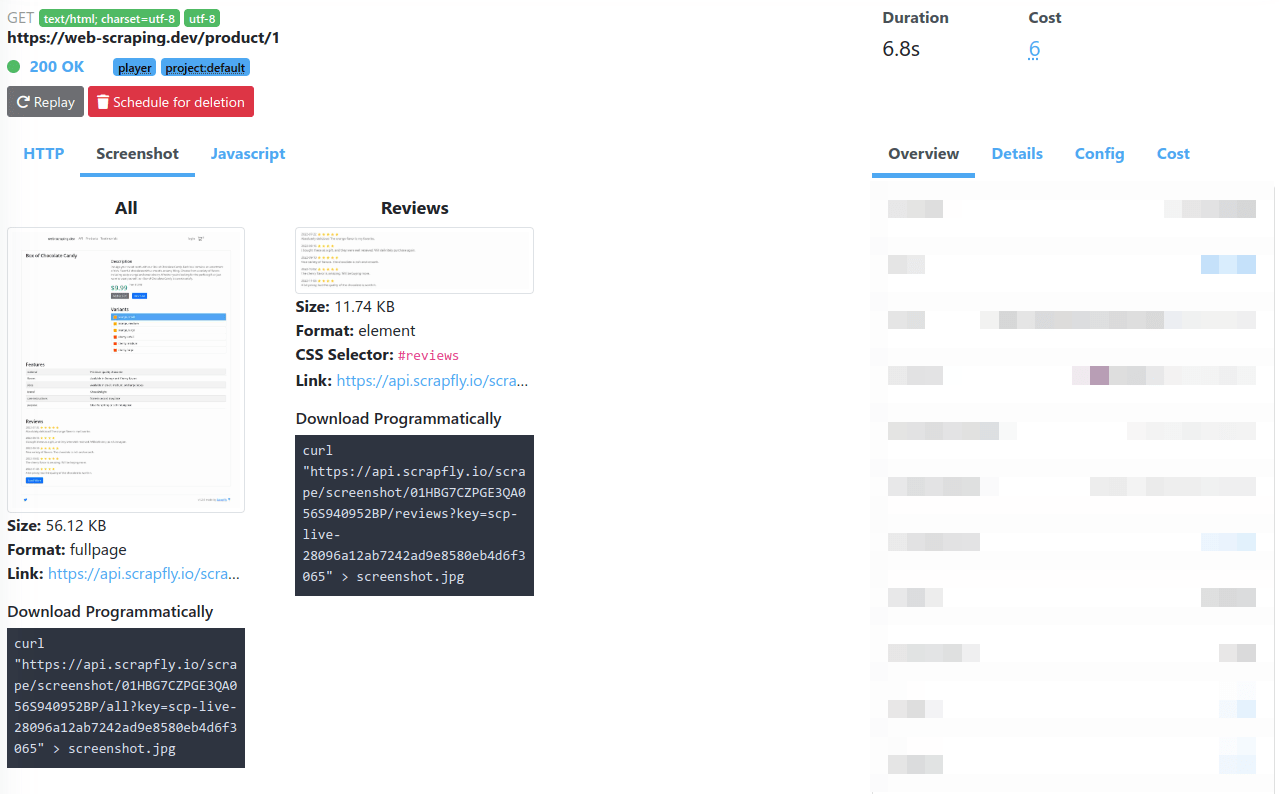
The screenshots feature is a great way to understand what is happening during a scrape. It can be used to debug a scraper or to monitor a website for visual changes.
Note that Scrapfly headless browsers are optimized for web scraping and do not render media files like images or videos, so they will not appear in the screenshots. If you need
to render images in screenshot, you must enable the flag screenshot_flags=load_images, see flags section for more information.
The screenshot feature works beside the scraper and do no affect or alter the scraped result.
A maximum number of 10 different screenshots can be taken per single scrape.
Usage
To use the screenshots feature the screenshots parameter must be set with screenshot name and the desired capture area:
fullpageis reserved value for capturing full page.- CSS selector can be used to target specific HTML elements.
For example, to capture the full page and the reviews section of this mock product page https://web-scraping.dev/product/1 we'd use two screenshot parameters:
screenshots[all]=fullpageto capture the whole page underallname. Thefullpageis a reserved value for capturing all page content.screenshots[reviews]=.reviewsto capture CSS selector targeting the reviews section underreviewsname
curl -G \
--request "GET" \
--url "https://api.scrapfly.io/scrape" \
--data-urlencode "render_js=true" \
--data-urlencode "screenshots[all]=fullpage" \
--data-urlencode "screenshots[reviews]=#reviews" \
--data-urlencode "key=__API_KEY__" \
--data-urlencode "url=https://web-scraping.dev/product/1""https://api.scrapfly.io/scrape?render_js=true&screenshots[all]=fullpage&screenshots[reviews]=%23reviews&key=&url=https%3A%2F%2Fweb-scraping.dev%2Fproduct%2F1"
"api.scrapfly.io"
"/scrape"
render_js = "true"
screenshots[all] = "fullpage"
screenshots[reviews] = "#reviews"
key = ""
url = "https://web-scraping.dev/product/1"
Example Of Response
Download Programmatically
The URL to download the screenshot is located in the response result.screenshots.${name}.url key.
However, this URL requires authentication and to view it the key parameter must be added with your Scrapfly key. For example using curl:
curl "https://api.scrapfly.io/4d1b8e8f-3803-4aa6-88fa-39d5aa81b6b3/scrape/screenshot/db475202-a7c0-4d7b-9179-98089901fce3/main?key=" > screenshot.jpgRelated Errors
All related errors are listed below. You can see the full description and examples of error responses in Errors documentation page.
Options / Flags
You can enable additional options for the screenshot feature by adding the screenshot_flags parameter to the scrape request. You can set multiple flags by separating them with a comma. Here is the list of supported flags:
load_imagesLoad images. +3 API Credit is billed per 100kb of media downloadeddark_modeEnable dark mode displayblock_bannersBlock cookies banners and overlay that cover the screenhigh_qualityNo compression on the output imageprint_media_formatRender the page in the print mode
Example
curl -G \
--request "GET" \
--url "https://api.scrapfly.io/scrape" \
--data-urlencode "render_js=true" \
--data-urlencode "screenshots[all]=fullpage" \
--data-urlencode "screenshots[reviews]=#reviews" \
--data-urlencode "screenshot_flags=load_images,block_banners,high_quality" \
--data-urlencode "key=__API_KEY__" \
--data-urlencode "url=https://web-scraping.dev/product/1""https://api.scrapfly.io/scrape?render_js=true&screenshots[all]=fullpage&screenshots[reviews]=%23reviews&screenshot_flags=load_images%2Cblock_banners%2Chigh_quality&key=&url=https%3A%2F%2Fweb-scraping.dev%2Fproduct%2F1"
"api.scrapfly.io"
"/scrape"
render_js = "true"
screenshots[all] = "fullpage"
screenshots[reviews] = "#reviews"
screenshot_flags = "load_images,block_banners,high_quality"
key = ""
url = "https://web-scraping.dev/product/1"
Limitations
The screenshots feature requires javascript rendering to be enabled in order to work. In some situations, the screenshot capture can fail or be ignored:
- GET Request: Only GET request are eligible for screenshot
- Javascript difficulties: For unusually javascript-heavy pages screenshot can fail as javascript execution can interfere with the screenshot capture mechanism.
- Cache: If the cache feature is used and cache is being HIT instead of the live page then screenshots will be ignored.
Frequently Asked Questions
- Question: How long are screenshot download links are valid for?
- Answer: Screenshot availability duration is determined by your log retention policy (starting at 1 week).
- Question: Why do some screenshots look different compared to a real browser?
- Answer: Scrapfly web browsers are optimized for web scraping, which can make visuals appear slightly different compared to real web browsers.
- Question: Can I limit the API Credit consumption when flag
load_imagesis set withcost_budget? - Answer: Bandwidth usage is not heuristic, we can't predict the consumption of a complete page - the budget limit will not have effect.